束善杭——独立咨询顾问,20年IT经验。历任亚信科技程序员、项目经理、研发总监、IBM高级咨询顾问和项目经理;后自主创业做二手车行业saas平台,主要担当产品经理职责,带领团队发展近万家二手车企业客户,平台支撑日GMV 10亿,DAU 10万终端用户。现仍继续创业中,转型为中大型企业提供跨系统整合IT系统的数字化转型和技术服务。
— 1 —
首个冲刺的服务设计
⊿ 商品上下文服务设计
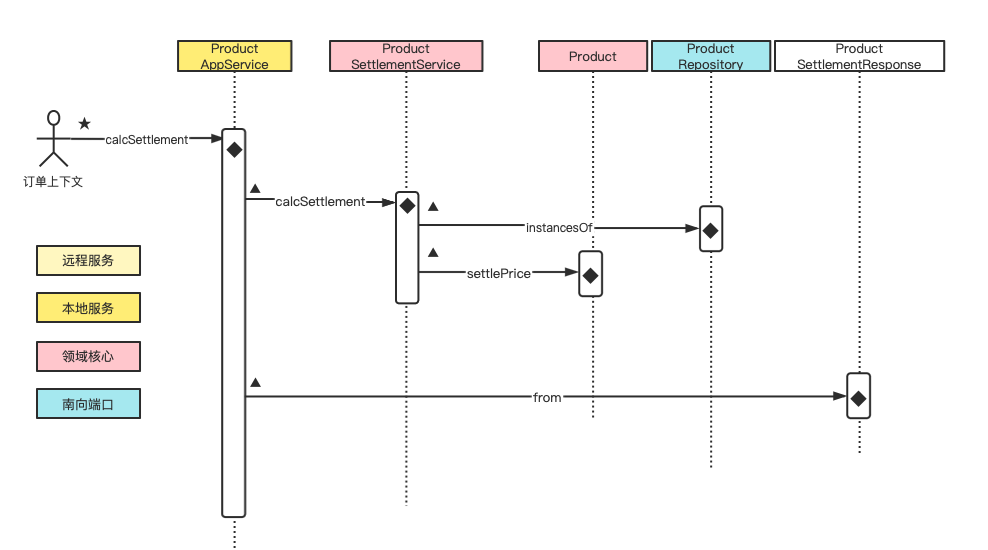
1、计算多商品结算信息
- 从数据库重建多个商品对象;(原子任务,资源库端口,访问数据库)
- 计算每个商品的结算价格和结算总价;(原子任务,聚合,实体对象行为)
- 转换为返回结构;(原子任务,发布语言类,数据格式转换)
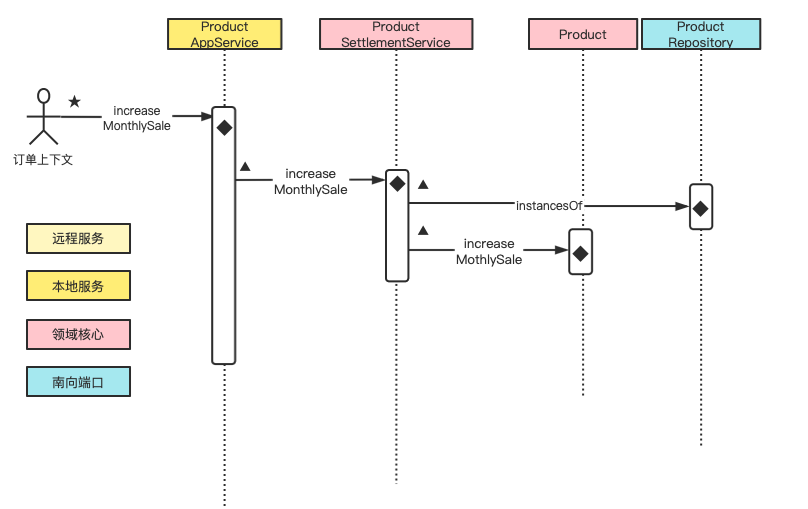
2、增加多商品销量
- 从数据库重建多个商品对象;(原子任务,资源库端口,访问数据库)
- 增加多个商品的当前月销量统计;(原子任务,聚合,实体对象行为)
3、搜索店铺内商品(CQRS)
同上个服务功能,该搜索功能放在“业务查询中心”微服务中,采用 CQRS 查询代码模型,不采用领域代码模型,故不做 DDD 战术服务设计。
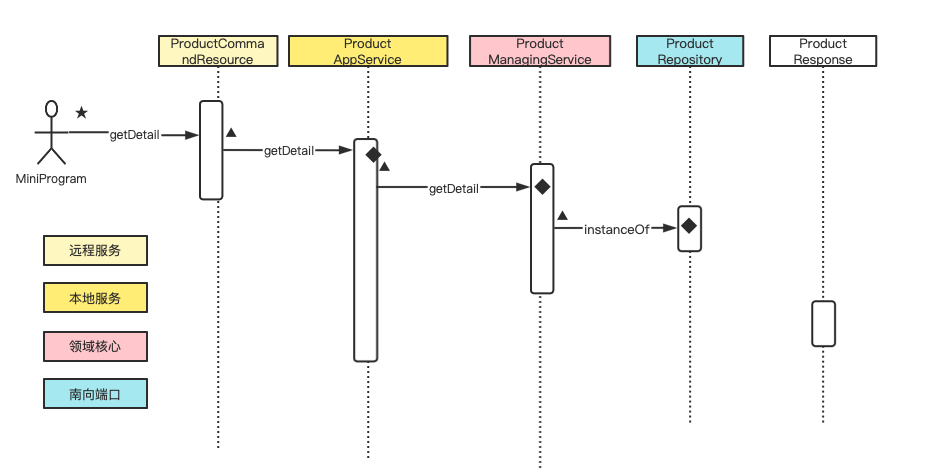
4、获取商品详情
这个服务功能其实是根据对象 ID 从数据库“重构”对象信息的功能,可以采用领域模型进行服务设计。服务功能分解如下:
- 从数据库重建商品;(原子任务,资源库端口,访问数据库)
- 转换为返回结构;(原子任务,发布语言类,数据格式转换)
⊿ 店铺上下文服务设计
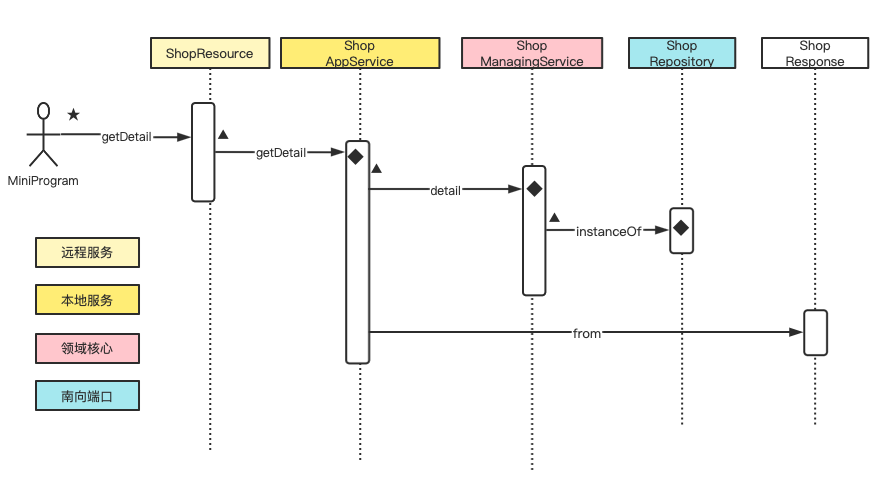
1、查询店铺信息
这个服务功能同样根据对象 ID 从数据库“重构”对象信息的功能。服务功能分解如下::
- 从数据库重建店铺;(原子任务,资源库端口,访问数据库)
- 转换为返回结构;(原子任务,发布语言类,数据格式转换)
⊿ 平台集成上下文服务设计
正如我们在战略技术决策中提到的,平台集成上下文涉及的领域知识简单稳定,不进行 DDD 战术设计。就用传统的 controller+service+dao 代码模型实现即可。
— 2 —
战术设计技术决策
⊿ DTO & VO 技术考量
DTO 和 VO 其实主要是在上下文之间(DTO)、微服务之间(DTO)、前端界面和后端服务之间(VO)用来传输信息的。由于为了避免上下文内部的业务逻辑“泄露”到其它上下文、或服务端逻辑“泄露”到前端界面,并且让它们之间尽可能的解耦,所以需要考虑设计一些“专用”的数据对象来传输信息。这种 DTO/VO 的数据对象,在 java 里面一般都是存粹的只有属性没有方法的“贫血”对象。将 DDD 实体对象的数据转换为 DTO/VO,往往都是一些“机械化”的 get/set 调用,很琐碎而消耗工作量。为此,一般引入专用的技术组件,帮助我们“自动化”实现这部分功能。
1、DTO 转换组件选择
从目前各类开发者社区能够找到的资料来看,实现这种领域实体对象到 DTO 数据转换的方法或工具,无非就是这几类:
(1)运行期转换:
- json 转换。就是将 DTO 转换为 json 对象、再将 json 对象转换为领域实体对象。这种方式性能差,且容易造成大量的字符串对象,大型应用系统会有大量 jvm 内存 gc。除非是很小业务量的系统(月请求量百万级以下),否则不建议采用。
- 反射机制转换。这是通过 java 反射机制来实现属性复制的,如:BeanUtils 类的 copyProperties 方法(apache 和 spring 分别有一个 BeanUtils 类)、Dozer、ModelMapper、BULL。这些方式的性能仍然不是特别好,同时也很难支持复杂对象的深度拷贝,所以也不是很适用于大型应用软件系统。
- 字节码方式转换。这种方式是利用 java 字节码进行拷贝,性能要好得多,如:beanCopier(基于 cglib 动态代理)、orika(基于 javaassist 代理)。但仍然要么功能有限(beanCopier),对复杂对象的深度拷贝能力不足;要么很久未维护了(orika),会影响到将来系统的可维护性。
(2)编译期转换:
- 这一类的开源技术组件,基本都是通过“配置+自定义转换代码”来实现复杂的对象转换,并且是在编译期完成代码的自动生成来实现的。典型代表有:MapStruct、JMapper、Selma 等。
- 这类工具的缺点是不能在运行时动态加载类型进行转换,每次修改 DTO 数据对象定义都需要重新编译代码。
- 鉴于大型应用系统一般都会遇到很多复杂的对象结构、以及需要支撑高性能、大业务量并发。相对动态加载 DTO 数据对象定义来说,性能和开发灵活性尤其重要。所以,这类工具的对比,主要是看运行性能和开发灵活性。
(3)编码指定转换关系:
- 这一类开源技术组件,是通过已经写好的类似工厂方法的方式,允许开发人员自行定义两个对象之间的转换关系,然后执行自动转换。典型代表有:datus、remap 等。
- 这一类的工具,还是有比较大的开发工作量,并且其还是依赖一定的反射机制,所以性能和开发便捷性均居中。对于大型应用系统来说,不推荐使用(当然,其实对于我们“群买菜”这个应用的实际使用来说,应用逻辑没那么复杂、业务量也还不算特别巨大,是相对合适的。但我们这里,并不仅仅是为了演示一个小系统的开发)。
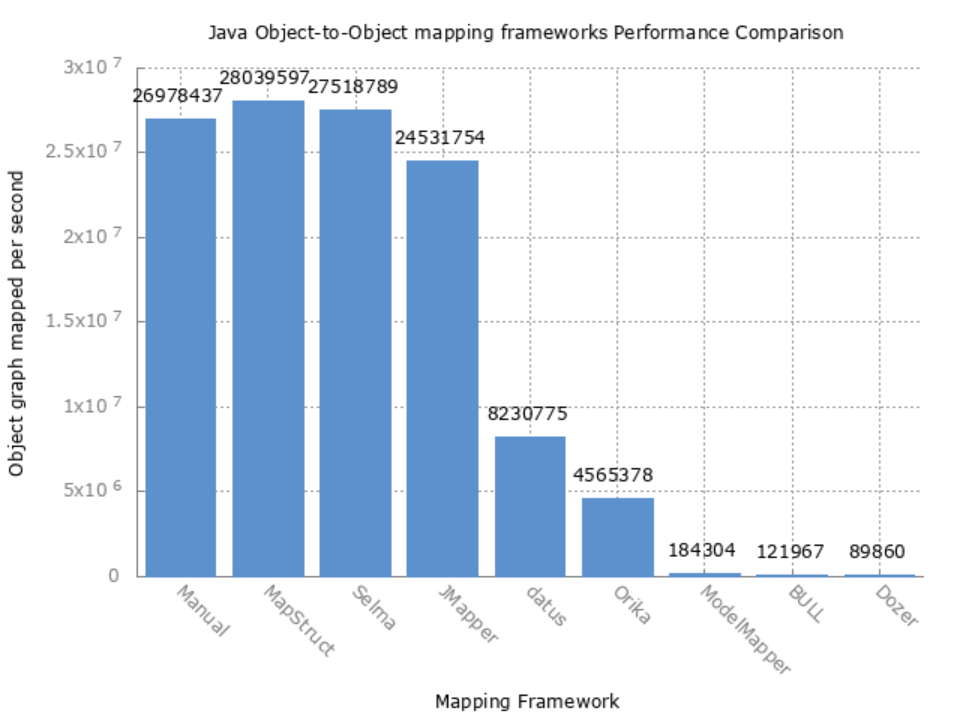
github 上专门有人做过各类转换工具的性能对比,如下图(网址:https://github.com/arey/java-object-mapper-benchmark):从上图的性能测试来看,我们这里选择 MapStruct 来作为我们的转换工具。
⊿ DTO/VO 实现策略
结合 MapStruct 的使用特点,我们采用如下的 DTO/VO 实现策略:
- 针对遵循 DDD 领域对象模型设计的限界上下文或模块(具体见前面的“战略设计技术考量”部分),我们采用 pl(发布语言)类作为 DTO,并且不再设计单独 VO 类。前端界面请求参数到后端服务 DTO 对象的转换,由 spring 框架自动实现;
- 针对未遵循 DDD 领域对象模型设计的限界上下文或模块,主要是业务查询中心(含商品、订单、商品的查询部分逻辑)、平台接入上下文,设计专门的、适配于前端界面的 VO 类,并将其和传统贫血模型的实体类(根据数据库表结构设计)之间做转换;
- 为此,按照 MapStruct 的使用方式,我们为每个 DTO 类均定义单独的 Mapper Interface,并在代码结构中将所有的 Mapper Interface 均放置在与对应 DTO 类(PL 类和 VO 类两种情况)相同的 package 位置。Mapper Interface 的命名风格,永远为“DTO 类名+Mapper 后缀”。如:OrderResponse 对应的 mapper interface 为 OrderResponseMapper,OrderSubmitRequest 对应的 mapper interface 为 OrderSubmitRequestMapper 等;
- 为了避免 DTO/VO 对领域核心模型、以及传统 controller/service/dao 代码架构中对业务层 service 和 dao 的“污染”,我们将前面两种 DTO(PL 类和 VO 类)与实体类相互之间的转换,均在 DTO 类的相应方法中调用 MapStruct 的方法来实现转换;
- 所有的 mapper interface 均采用 MapStruct 的 componentModel=”spring”的配置方式来在 spring 框架中注入 bean 供 DTO 类使用;
⊿ 资源库实现策略
1、 JAVA ORM 框架选择
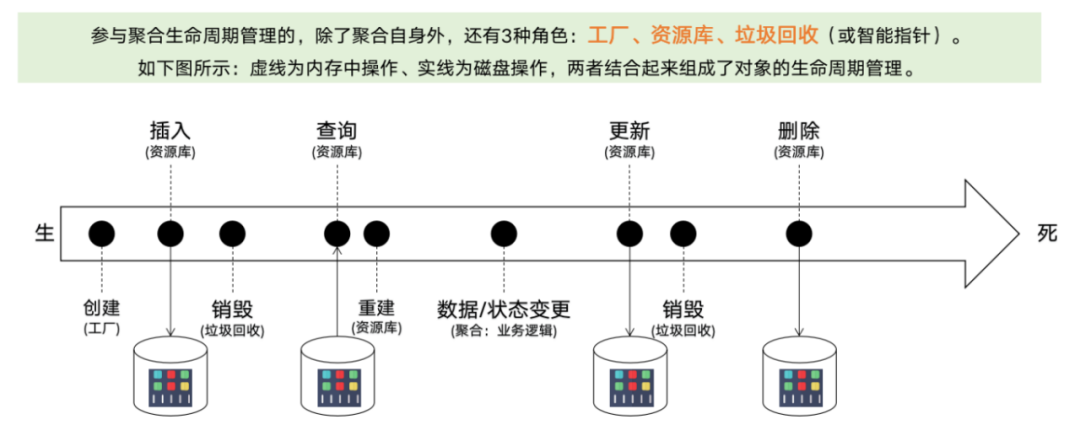
在 DDD 战术设计方法中,是先有领域模型、再有数据模型的。也就是说,数据模型是为了满足领域模型而设计的。理论上来说,如果不考虑各种复杂的数据查询逻辑、以及可能的数据处理性能风险,与 DDD 战术设计思想最配套的数据库,可能就是 mongodb 这种通过类似 json 字符串(其实是 bson)存储数据的平台。这种数据库中,天生就是一个“聚合根实体对象”(如:订单聚合根)对应一条“数据记录”。当然,我们不能想当然的就将所有应用系统的数据库都用 mongodb,还是要结合实际情况(主要是性能问题)使用类似其它的数据库如:oracle、mysql、postgresql 等。为此,我们需要选择合适的 ORM 框架来实现“实体对象模型”和“关系数据模型”之间映射(这就是 ORM 这一词的本来含义)。目前市面上可用于 java 开发的 ORM 框架,包括 Hibernate、OpenJPA、Mybatis、TopLink、Spring Data JPA(其实是 Hibernate 的封装)等等。为了确定合适的 ORM 框架,按照前面战略设计技术决策中所述,我们有两种代码模型:DDD 领域设计代码模型、CQRS 的传统查询代码模型。我们需要考虑这两种代码模型分别选用哪种 ORM:首先,我们来看 DDD 领域设计代码模型所需要的 ORM。按照前面的战略技术决策,这里涉及到“业务查询中心”和平台集成上下文之外的所有内容。这需要我们首先对 DDD 战术设计的“实体对象”的生命周期做更深一步的分析。其实,我们要看的不是单个“实体对象”的生命周期、而是整个“聚合”的生命周期。因为按照 DDD 战术设计思想,一个聚合才能有一个完整的生命周期,而不是单个实体对象。如下图所示,这是“聚合根”实体对象在 DDD 战术设计中所提倡的生命周期的一个完整描述:
- 除了工厂和垃圾回收(或智能指针)外,参与聚合生命周期最重要的技术手段就是资源库了(其中工厂如何实现在前面的服务设计中已经说过了);
- 资源库参与聚合生命周期最重要的职责,就是完成聚合对象的“插入、重建(查询)、更新、删除”这 4 个操作;
- 需要注意的是:资源库是跟聚合一一对应的。也就是说:一个聚合只会有一个资源库。这就带来一个问题:如何实现“聚合内部其它实体对象”的“插入、重建、更新、删除”操作呢?答案是:在资源库进行“插入、重建、更新、删除”操作时,将“整个聚合”整体进行“插入、重建、更新、删除”,而不再单个实体对象上进行“插入、重建、更新、删除”操作。
这里就提出了 ORM 框架选择时最重要的一个需求:对“聚合”整体而非单实体对象进行“插入、重建、更新、删除”操作。这就会引起另一个问题:在实际业务中,很可能某个业务操作,只对聚合内多个实体对象的很少一部分实体的数据和状态进行了修改,这种情况下避免大量的“无效持久化”而引起性能问题或资源浪费呢?这里所谓的“无效持久化”,指的是实际上数据并没有修改、但我们在数据库中进行了操作(对关系数据库来说就是 SQL 操作)。为了更加清楚的表达这个问题,我们来举一个实际的例子:比如,在“客户提交订单”界面上,客户对订单行的某个商品进行“增减”操作,这其实只是修改了“订单”聚合中某个“订单行”实体对象的“下单数量”属性进行了修改,同时对应的修改了订单总价。而如果我们将“订单”聚合的所有对象对应的数据库记录都全部“简单粗暴”的更新一遍,则可能包含(参见我们前面订单的聚合设计):订单表(对应 Order 实体)、订单行表(对应 OrderItem 实体)、订单支付表(对应 OrderPayment 实体)、订单操作日志表(对应 OrderOperLog 实体)、订单商品快照表(对应 OrderProduct 实体)这么多表的所有记录,并且每个记录都是“delete+insert”SQL 操作。这种实现方式,显然是不合理的!为此,我们需要 ORM 框架支持这些实体对象的“缓存更新”功能:也就是说,在我们对“聚合”进行整体更新时,ORM 框架能够支持自动判断聚合中哪些实体对象的属性值被修改了、哪些没有修改,然后其自动对被修改的实体对象执行 update SQL 操作。另外,在聚合“重建”操作中,我们也希望 ORM 框架自动实现这样的“lazy load”逻辑:只有在本次业务服务中,需要用到的那些实体对象才被真的执行 select SQL 操作加载到内存中,而不是聚合的所有对象。从这个角度考虑,我们能够选择的只有基于 JPA 规范(支持我们上面提到的那种“缓存更新”和“lazy load”)实现的 ORM 框架。而目前 java spring 开发框架下,我们还是采用被广泛使用的 Spring Data JPA(基于 Hibernate)比较好。其次,我们来看 CQRS 的传统查询代码模型选用的 ORM。按照前面的战略技术决策,这里主要涉及到“业务查询中心”,即商品、订单、接龙的 3 个上下文的“查询”部分。考虑到这些查询一般都会很灵活变化的需求(随着用户体验设计的调整而调整、随着业务需求的调整而调整等等),需要有很灵活的 SELECT SQL 编写要求,故建议使用 MyBatis Plus 以便于可灵活定制 SQL 语句。
2、资源库实现方案
对于领域模型的代码来说,需要实现资源库。按照 Eric 在《领域驱动设计软件核心复杂性应对之道》中的描述,资源库具有类似集合的特性,可向其插入或更新实体对象,并由其实现聚合内实体从数据库的重建、以及向数据库持久化聚合。我们在实现资源库时,需要考虑如下两方面的因素:
- 需考虑资源库针对具体底层数据库的独立性,允许在底层数据库替换为其它数据库时,领域层对资源库的使用不变;
- 需实现仅仅是资源库对应聚合的相应操作,而不用过多的实现其它的数据持久性相关特性;
- 与此同时,考虑到涉及到数据库的操作其实是有很多共性的。如果每个聚合对应的资源库实现时,如果重复实现相同的数据持久化操作逻辑,就会显得很繁琐而没有必要。为此,我们采用如下的资源库实现策略:
- 所有的资源库采用接口方式定义其所对应聚合所需要的操作,而具体实现则采用 DI(依赖注入)的方式注入到应用系统中去。这样做的好处,就是领域层(主要是领域服务)对资源库的使用,就不会对底层具体数据库技术产生依赖。
- 针对具体的底层数据库,实现一个通用的资源库模板类,并在所有资源库实现类中定义该模板类的私有成员变量来重用模板类的数据库交互逻辑。
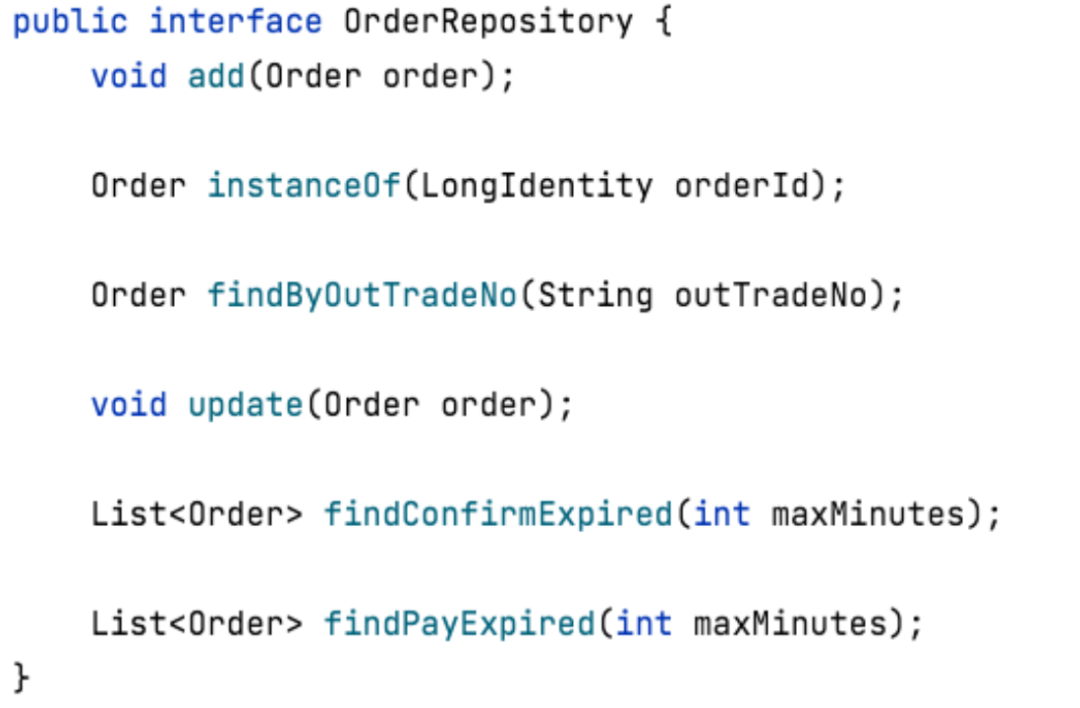
从代码表现来看,我们采用如下方式的代码来实现资源库(这里以订单聚合对应的订单资源库为例):
DDD理论体系的落地,将涉及到需求分析、战略设计、战术设计等内容,并涉及到当下时兴的云原生微服务架构如何落地的实操内容。敏捷开发过程主要结合scrum管理过程,以及TDD(测试驱动开发)编程过程。
7月3-4日,即将于深圳举办的2022K+全球软件研发行业创新峰会上,束善杭老师将带来《DDD实战:将DDD理论落地到敏捷开发中的过程和方法》主题演讲。将深入讲解如何将DDD理论体系与实际敏捷项目开发过程结合,给出完整的工作流程,并针对流程每个环节给出具体操作方法的讲解,以及工作成果展示等。
现在报名还可享受早鸟钜惠价,立减2040元!赶快扫码报名吧!