
作者:刘焕勇——360人工智能研究院知识图谱方向算法负责人,曾就职于中国科学院软件研究所。主要研究方向为大模型数据挖掘与自动化评估、领域知识/事件图谱的构建与落地应用,申请发明专利十余项、论文数篇。近年来在OGB-Wikikg2、CCKS多模态实体对齐等评测中获得多项冠亚军。
▼

1、静态知识图谱SKG
第一代知识图谱是静态图谱,以实体和实体间关系的形式呈现知识。
静态知识图谱定义为:SKG={En,R,F},其中En和R分别代表实体集和关系集。F⊆En×R×En是一组事实{(es,rp,eo)},其中es,eo∈En,rp∈R。
事实(es,rp,eo)表示在某个未指定的时间,主体实体es和客体实体eo之间存在关系rp。
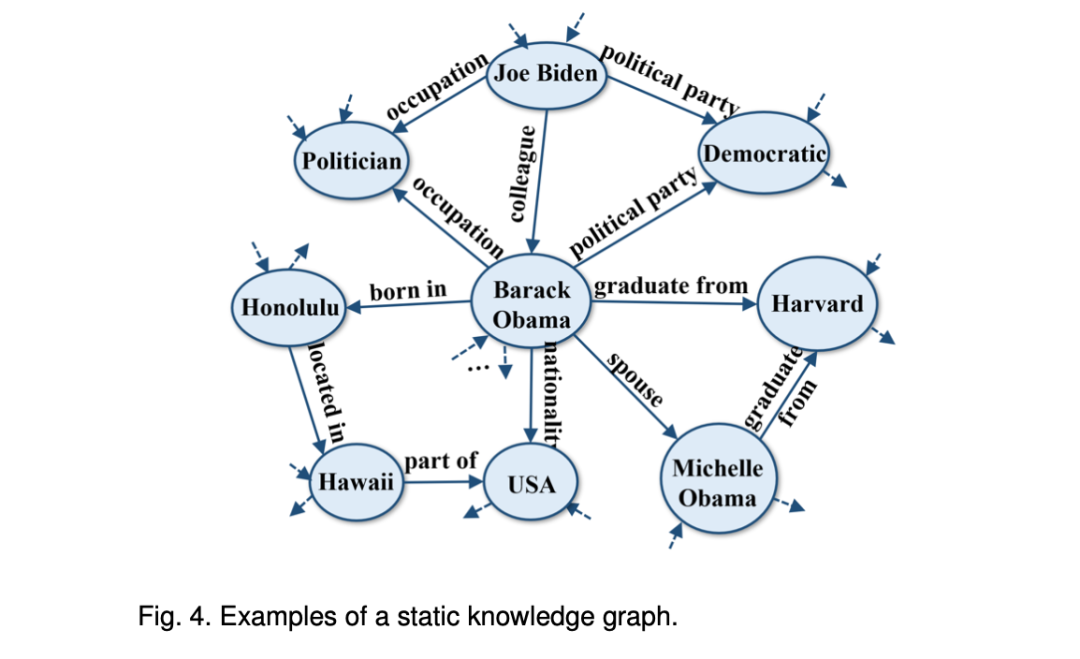 例如,Kinship数据库是一个小型关系数据库,由两个家族的24个独特名称组成。HowNet是一个语义知识库,旨在捕捉汉语中词语和概念的含义。这两个知识库是特定实体和概念之间关系的静态再现,创建后不会更新。
例如,Kinship数据库是一个小型关系数据库,由两个家族的24个独特名称组成。HowNet是一个语义知识库,旨在捕捉汉语中词语和概念的含义。这两个知识库是特定实体和概念之间关系的静态再现,创建后不会更新。WordNet是一个英语词汇和概念的词库,其中包括同义词和超义词。Freebase的设计目的是成为一个开放和共享的结构化数据存储库,存储有关人物、地点、组织等广泛主题的数据。由于它们已经很久没有更新,因此可以被视为SKG。
SKG对许多应用都很有用,如信息检索和问题解答,因为在这些应用中,实体之间需要一套固定的关系。但是,它们并不适用于需要最新信息的应用,如新闻文章或社交媒体馈送。
2、动态知识图谱DKG
第二代知识图谱引入了变化和更新的概念,保证了知识的时效性和图谱的可扩展性。
动态知识图谱定义为:DKG={En,R,F},其中En和R分别代表实体和关系的动态集。F⊆En×R×En是事实{(es,rp,eo)}的动态集合,其中es,eo∈En,rp∈R。事实(es,rp,eo)表示在最新更新时,主体实体es和客体实体eo之间存在关系rp。

例如,DB-pedia是从维基百科中提取结构化数据创建的DKG。它会定期更新,以反映维基百科的变化。同样,许多大规模的知识图谱,如谷歌知识图谱(GoogleKnowledgeGraph)、NELL、关联开放数据(LinkedOpenData)、OpenCyc、概念网(ConceptNet)和UMLS,也会随着时间的推移不断更新,甚至是实时更新,以反映底层数据的变化。这些图的设计比SKG更灵活,适应性更强,可以更好地处理不断变化和发展的数据。
值得注意的是,DKG的单独版本可被视为SKG。不再更新的DKG也会退化为SKG。因此,SKG可以看作是DKG的特例,
DKG正被用于各种应用中,包括搜索引擎、推荐系统、聊天机器人等。通过不断用最新数据更新KG,这些系统可以为用户提供更准确、更相关的结果。然而,由于历史数据的丢失,DKGs无法应用于历史分析、趋势分析和预测等应用中。
3、时序知识图谱TKG
第三代知识图谱增加了知识的时间维度,可以表示实体之间随时间变化的关系。时态知识图谱旨在捕捉和表示随时间变化的知识,其时间敏感性往往是动态的。
时态知识图谱定义为TKG={En,R,T,F},其中En、R和T分别代表实体、关系和时间戳的可扩展集合。F⊆En×R×En×T是事实{(es,rp,eo,t)}的可扩展集合,其中es、eo∈En,rp∈R,t∈T。事实(es,rp,eo,t)表示在t时间,主体实体es和客体实体eo之间存在关系rp。t有时是未知的,可以用不同的形式表示,如时间点或时间间隔。
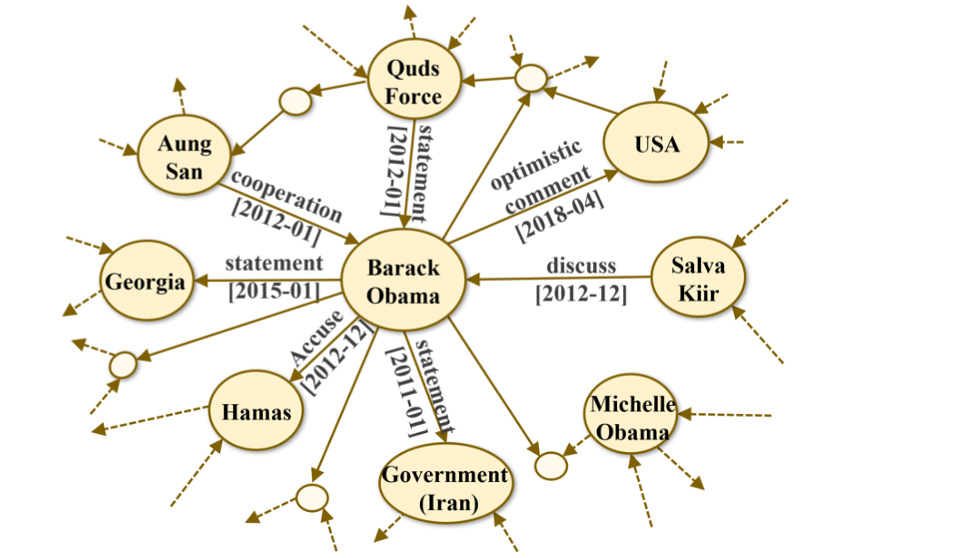
SKGs和DKGs以三元组的形式表示事实,如(唐纳德-特朗普,美国总统)。事实成立的时间跨度是未知的。因此,人们无法使用SKGs或DKGs来处理时间敏感型任务,如时间感知链接预测、预报等。
许多大型TKGs,如Wikidata、YAGO,都将事实三元组与有效的时间注释联系在一起。一些事件数据库,如ICEWS和GDELT,也可以被视为TKG,因为它们将事件新闻分解为事实四元组并加以存储。这类TKG提供了丰富的时间信息,但TKG中的每个事实并不都包含时间戳。因此,DKGs可被视为TKGs的特例,在这种情况下无法获得所有时间信息。
总的来说,TKGs提供了更全面的时间数据视图,这对包括时态查询回答和预测分析在内的广泛应用非常有用。另一方面,有些TKG虽然是从事件新闻中提取的,但由于其表示方法以实体为中心,因此不能有效地表示事件信息。
4、事件知识图谱EKG
最新一代的知识图谱侧重于表示和理解事件,即涉及多个实体和关系的、有时间限制的事件,从而能够表示实体和事件之间复杂的、随时间变化的关系。
事件知识图谱定义为:EKG={E,R,T,F}.E=En∪Ev是节点集,其中Ev是可扩展的事件集。R表示实体与事件之间的关系集。F⊆E×R×E×T是一个可扩展的事实集{(es,rp,eo,t)},其中es,eo∈E,rp∈R。事实{(es,rp,eo,t)}表示在时间t主节点es和客节点eo之间存在关系r。r可以是实体-实体关系ren-en∈Ren-en,或事件-事件关系rev-ev∈Rev-ev,或实体与事件之间的关系ren-ev∈Ren-ev,其中R=Ren-en∪Rev-ev∪Ren-ev。
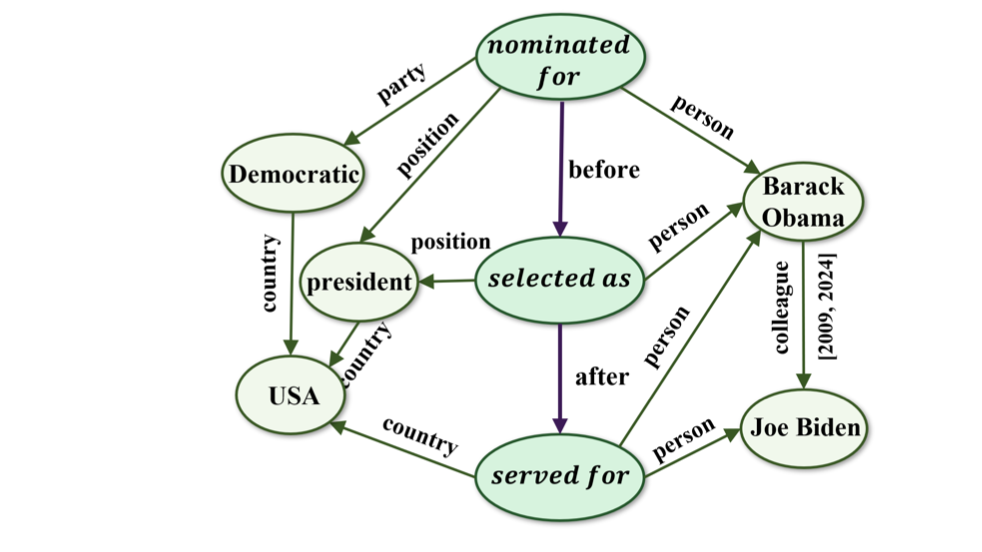
EEG是一种EKG,其中事件节点是抽象、概括和语义完整的动词短语,边代表它们之间的时间和因果关系。EventKG是一种以事件为中心的多语言TKG,它聚合了以事件为中心的历史和当代事件信息和时间关系。ELG是一种EKG,主要侧重于模式级事件知识。另一方面,EvGraph是一种自动构建管道,可将新闻报道结构化为EKG。
与TKGs相比,EKGs多了一种节点类型(即事件节点)和两种关系类型(实体-事件关系、事件-事件关系)。EKG的基本应用包括脚本事件预处理、时间线生成和归纳推理。
此外,EKG还能促进与事件相关的下游应用,如金融量化投资和文本生成。
1、知识抽取的一些方案
不同类型知识库的构建依赖于不同的知识提取技术。构建SKG需要从文本中提取事实三元组。因此,其知识提取过程主要包括命名实体识别(NER)和关系提取(RE)。
同时,DKGs的构建需要从不断变化的现实世界信息中进行动态知识提取。TKGs和EKGs的构建还需要进行事件抽取,以获得相应的时间和事件信息。
此外,KG中关系之间的逻辑规则可视为事实知识之外的一种特殊知识,对不同类型KG的规则发现需要不同的规则提取技术。
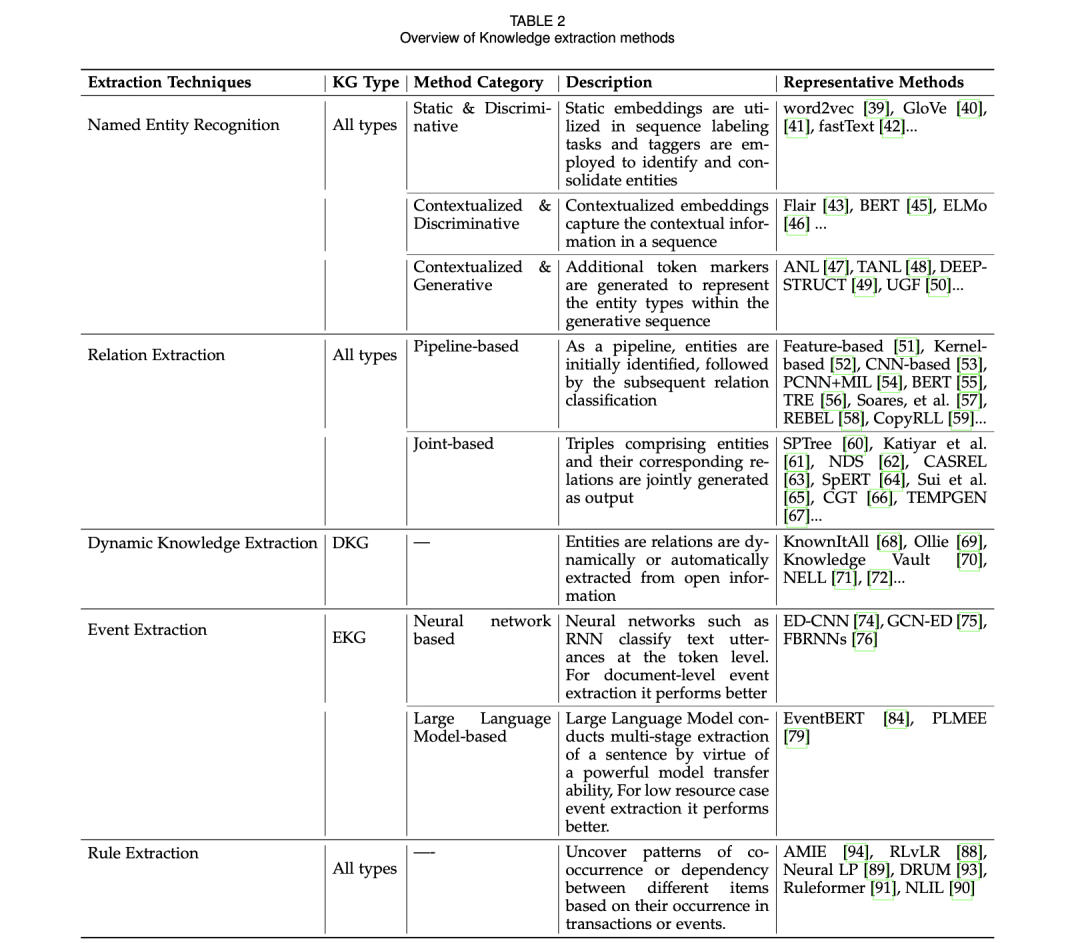
随着大型语言模型(LLM)的兴起及其强大的自然语言理解能力,LLM被广泛应用于各种知识抽取任务中,表2中列举了其中的一些常用的方案:
包括实体识别(Named Entity Recognition)、关系抽取(Relation Extraction)、动态知识抽取(Dynamic Knowledge Extraction)、事件抽取(Event Extraction)以及规则抽取(Rule Extraction)。
2、知识推理的一些方案
考虑到所收集数据的固有局限性,仅靠知识提取不足以捕捉全部知识,这些局限性凸显了对知识推理的需求,通过推断缺失的实体和关系来补充知识。
此外,KGR还可以利用构建的知识库来帮助下游任务。因此,KGR对于创建全面有效的KG也至关重要。
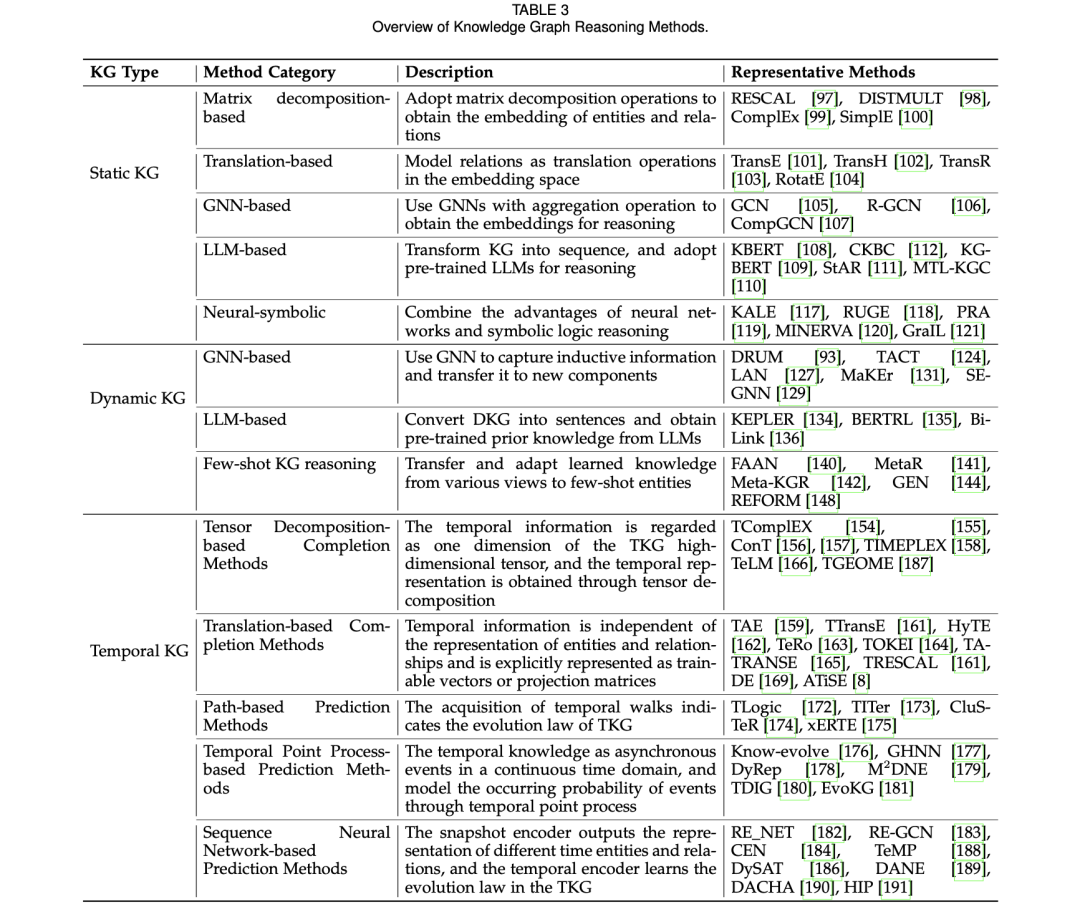
早期的KGR工作主要集中在SKGR上。然而,这些方法并不适用于其他类型的KG。为此,后来又有人提出了针对DKGR和TKGR的多种方法。表3列举了一些常用的方法:
知识图谱和大型语言模型代表了截然不同的知识表示范式。知识图谱是最具代表性的符号化知识形式,通过结构化信息提供可解释性,但可能缺乏灵活性。LLM是最强大的参数知识形式,在生成性和适应性方面表现出色,可以处理各种任务,但在决策方面可能不透明。为了深入了解KG和LLM的异同,指导两者未来的整合与应用,我们建议对两者进行全面比较。
1、相同点
KG和LLM的主要相似之处有三点:
(1)数据源都来自海量的非结构化数据;
(2)都可以表示实体语义,并存储实体之间的相关性;
(3)都可以作为知识源用于下游应用,例如问题解答。
LLMs的训练需要大量文本数据,这些数据通常从公开的互联网站获取。大规模知识库的构建也依赖于从非结构化开放数据中提取信息。
有些LLM和大规模KG甚至使用相同的数据源。例如,维基百科是很多LLM(如BERT)最重要的训练语料,也是一般KG(如DBpedia和YAGO)的主要数据源。
KG通过记录实体的类型、属性和描述以及它们之间的关系来表达实体的语义信息。另一方面,LLM在文本数据上进行训练,以获得实体的字符级嵌入或词级嵌入,这也可以表示实体的语义。LLMs也被证明能够在不进行微调的情况下召回关系知识。
具体来说,要使用LLM回答查询(JoeBiden,place_of_birth,?),可以输入一个屏蔽句"JoeBiden出生于[MASK]"或一个自然语言生成(NLG)任务"WherewasJoeBidenborn?[MASK]"来探究关系知识,其中MASK是要预测的对象实体的占位符,"wasbornin"是关系"place_of_birth"的提示字符串。以往的研究表明,这种范式在一些知识探测基准(如LAMA)上表现良好。
此外,一些后续研究提出了各种自动生成提示的方法,以进一步提高LLM的探测性能。
大规模知识库通常是一些下游应用(如知识库问题解答(KBQA)系统)的主要知识源。LLM的兴起使得在不访问外部知识的情况下执行此类下游任务成为可能,例如闭卷QA。
例如,BERT已被证明在开放域QA方面表现出色。一些文献表明,经过微调后,此类LLM在开放域质量保证方面的性能可进一步提高。
2、差异点
为了说明LLMs和KGs之间的差异,我们分别讨论了KGs相对于LLMs的局限性,以及LLMs目前相对于KGs能力的局限性。我们对幼稚园的局限性总结如下:
(1)构建成本高:知识边缘图的构建需要复杂的NLP技术来处理文本,并进行质量检测以确保知识的准确性。因此,大规模知识图谱的构建和维护通常需要大量人力。
(2)数据稀疏:由于人力成本高,KG所覆盖的领域和数据量有限,导致KG中存在大量缺失数据。
(3)缺乏灵活性:KG的存储结构和查询方法相对固定,难以适应各种数据结构和查询要求。相比之下,LLM可以为不同类型的下游任务提供更好的扩展性和表达性,因此具有更广泛的应用场景。
虽然LLM在推理能力和通用性方面优于KG,但LLM仍存在一些明显的局限性,可以通过与不同类型的KG结合来解决、
首先,LLM与SKG
LLM本质上是黑箱模型。我们很难知道LLM所给出答案的依据以及相应的推理过程。与此同时,KG的主要优势之一是其可解释性。我们更容易知道答案是如何通过KG推断出来的。
此外,无论知识更新和修订情况如何,SKG都能对查询给出一致的答案,无论该查询被执行多少次。相比之下,LLM由于其随机性和概率模型的性质,可能会对同一个问题给出不同的答案。而且,用于LLM的训练语料库可能存在噪声。LLM的训练过程有可能学习到不正确或有毒的知识,而知识的可靠性则需要通过KG的质量评估来保证,尤其是针对特定领域的小型KG。
其二,LLM与DKG
LLM可能会受到过时知识和信息的影响,因为它们是根据特定时间的互联网数据预先训练的。而且LLM的可编辑性有限,也就是说,由于其训练成本难以承受,LLM很难快速学习新的知识和信息。
例如,最大的GPT3模型的参数数量为175B,单次训练费用为1000万美元。相比之下,DKGs修订和更新其存储的知识要容易得多。因此,如果LLM和DKG能够有效结合,而无需昂贵的培训过程,那么LLM的知识更新成本将大大降低。
其三,LLM与TKG
LLM在处理时间信息时面临三大挑战。第一个挑战是平均化,即模型可能会看到相互矛盾的时间范围信息。第二个挑战是遗忘,即模型可能记不住只在某一代表性时间段内有效的事实,因此在被问及更遥远的过去时表现不佳。第三个挑战是时间校准能力差,也就是说,随着LLM变得"陈旧",它们越来越有可能被询问训练数据时间范围之外的事实。相对而言,TKG的时间范围往往更长,而且TKG中的事实知识对时间的敏感性更高。
其四,LLM与EKG
LLM在许多NLP任务中都取得了明显的成功,但在以事件为中心的任务中,它们仍然举步维艰。LLM在学习以事件为中心的知识方面的一个主要缺点是,它们可能无法有效捕捉事件之间的时间关系。这是因为LLM是通过自监督学习方法在大型文本语料库中进行训练的,可能无法访问结构化数据来帮助它们学习事件的时间关系。此外,以事件为中心的知识更新非常快,LLMs很难从不断增加的以事件为中心的新知识中学习。
除了各自的局限性,KGs和LLMs存储知识的表示形式不同,进行知识推理的方式也不同。虽然LLMs在LAMA上获得了不错的知识探测性能,但一些后续工作为LLMs提出了更困难和特定领域的探测数据集、,并证明当前的LLMs在事实知识提取方面并不可靠、,这与LLMs可被视为知识库的观点背道而驰。因此,有必要解决LLM现有的局限性,将各种知识库结合起来。
因此,两者之间仍有很大的整合潜力。
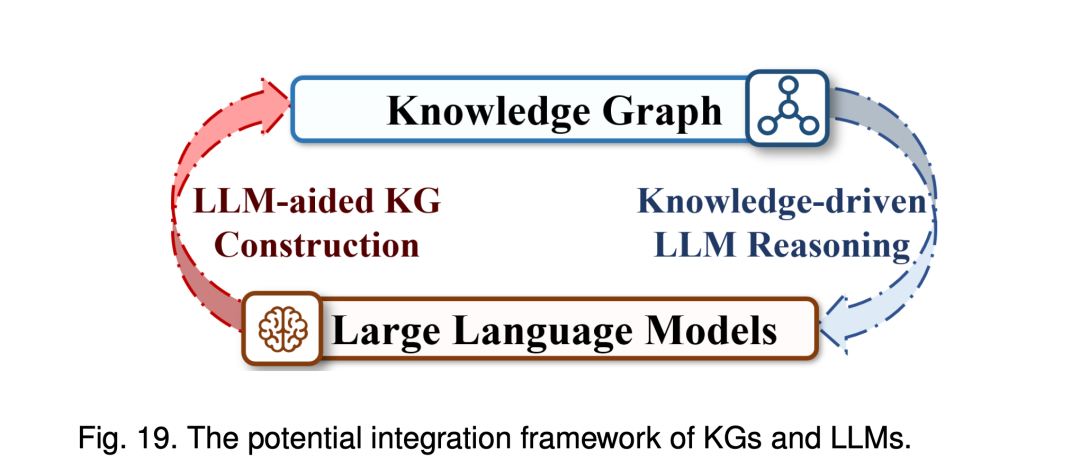
具体来说,从LLM辅助KG构建的角度来看:利用LLM的文本处理能力,KG可以在构建阶段实现更高效的无监督知识边缘提取,从而增强其自动构建和编辑能力。此外,LLM还能为KG提供无监督的质量控制和维护,确保知识的质量和准确性。在知识推理方面,LLM的模式归纳能力为神经符号推理提供了新的机遇。
从知识驱动LLM推理的角度来看:KG作为包含逻辑知识和事实知识的知识库,提供了更丰富的信息来源。在训练阶段,未来的研究将越来越多地探索如何将结构化的高质量知识与LLM结合起来,例如使用图神经网络进行知识编码或采用新的编码策略。这些方法不仅能丰富模型的知识库,还能优化其结构和训练目标。在推理阶段,整合知识库以检测和减少知识错觉,提高模型输出的可靠性和准确性将是一个关键的研究方向。
本文主要介绍了《On the Evolution of Knowledge Graphs: A Survey and Perspective》这一文章,该文章对知识图谱的分类有一定的启发意义,感兴趣的可以再看原文,会有更多收获。
总之,KGs和LLMs的整合将为人工智能领域带来创新。通过互补,两个实体都有可能实现更优越的性能和更广泛的应用场景。
参考文献:https://arxiv.org/abs/2310.04835.pdf
END
11月24-25日,一场聚焦于AI大语言模型的年度盛会,“AI+软件研发行业数字峰会(AiDD峰会)”即将于深圳举办。特邀刘焕勇带来《KG+LLM在行业知识管理场景的应用》主题演讲,将围绕知识图谱+大模型的一些结合探索展开报告,首先对大模型存在的幻觉来源、起因以及评估进行论述,然后对其在行业知识管理、搜索及问答场景中的一些具体案例进行介绍。
 双11特惠
双11特惠
好基友同行,第二人半价



北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

