
▼
谷歌最新推出的 Gemini AI 模型在首次亮相后,评论褒贬不一。但在人们发现该公司演示中最引人注目的部分几乎完全是伪造的后,用户对谷歌技术不再那么信任,对谷歌的诚信表示怀疑。
一段标题为《与 Gemini 互动:体验多模态 AI》的视频首发当天观看量达到一百万,其受欢迎的原因并不难理解。这个令人震惊的演示“展示了我们与 Gemini 互动的一些精彩时刻”,显示了这款多模态模型(即理解并结合语言和视觉理解能力的模型)如何能够灵活应对多种输入。
首先,它描述了一只鸭子的草图是如何从一条简单的线条演变成一个完整的画作,随后表示这是一种不切实际的颜色。接着,它在看到一个蓝色的玩具鸭时表现出惊讶(“真是奇怪!”)。之后,它回应了关于那个玩具的多个语音查询。演示接下来展示了其他炫目的功能,如在换杯子游戏中追踪一个球,识别影子手势,重新排列行星的草图等等。
这一切反应都非常迅速,尽管视频中提醒说 “延迟时间已经缩短,Gemini 的输出也已经缩减”。所以他们省略了这里的迟疑和那里的冗长回答。总的来说,这是一个在多模态理解领域震撼人心的展示。
相信看过 Gemini 演示视频的人,多数都对它的“多模态能力”印象深刻。例如,Gemini 看到一只鸭子从草图到填色的整个过程,可实时给出解释和反馈,还能在换杯游戏中追踪纸团、辨别各种手势、重新排列行星草图等——短短 6 分半的视频,Gemini 给人的感觉是:仿佛可以实时观察周围世界并及时做出反应,还能与人类进行流畅的语音对话。
对于 Gemini 如此强大的能力,谷歌给出的解释是:Gemini 是 AI 的新品种,即“原生多模态”。
“我们将 Gemini 设计为原生多模态,从一开始就针对不同模式进行了预训练。然后我们使用额外的多模态数据对其进行微调,以进一步完善其有效性,这有助于 Gemini 从头开始无缝地理解和推理各种输入,因此远远优于现有的多模式模型。此外,Gemini 的多模态功能几乎在每个领域都是最先进的。”
听起来似乎有理有据,于是当一众网友都沉浸于 Gemini 的强大、好奇它能否真正超越 GPT-4 的时候,彭博社作家 Parmy Olsen 突然发出了一个“不太和谐”的声音:Gemini 的视频演示效果,是假的。
一石激起千层浪!好在 Parmy Olsen 并没有吊人胃口,很干脆地将谷歌的作假手法和证据全部公开:Gemini 并不能像视频中那样实时语音回答——它看到的只是视频片段中的静态图像,其语音也只是在读出人类给它的文本提示,且响应时间比视频中展示的要长。
举个例子,Gemini 演示视频中有一段识别动态手势的片段:通过观察左边不断变化的手势,Gemini 回答道,“我知道你在干嘛!你在玩石头剪刀布!”

这段视频乍看之下,你是不是以为可以实时向 Gemini 展示不同的东西,并与它交流?但事实并非如此:Gemini 仅支持文本交流,并不能进行语音对话。
根据谷歌公布的文档内容显示,这段视频显然是经过“加工”的:
(1)先给 Gemini 陆续展示三张单个手势的图片,问它分别看到了什么;
(2)再把三张手势图片一起发给 Gemini,问它这是在干什么,并提示是一个“游戏”;
(3)通过以上一步步的提示和引导,Gemini 最终给出了答案:你在玩石头剪刀布。

针对以上步骤,一位谷歌发言人解释道:“为了测试 Gemini 在各种挑战中的能力,我们通过捕捉录像来制作演示。然后我们使用录像中的静态图像帧提示 Gemini,并通过文本进行提示。”
Parmy Olsen 将其简单翻译了一下:“谷歌拍下了那双手做很多事情的画面,然后一张一张地向 Gemini 展示了这些镜头的照片。所以根本没有语音对话,而是跟 ChatGPT 和 Bard 一样的文本交流。”
此外,谷歌发言人还补充称,用户的配音都是从实际提示中摘录的真实内容,用于生成随后的Gemini输出结果——对此,Parmy Olsen 的翻译是:“你在视频中听到的声音,只是在朗读文字提示。”
也就是说,谷歌所展示的 Gemini 演示视频,是省略了所有引导提示、跳过了等待响应的时间、并用配音合成的最终结果。
Gemini 真如宣称的那样强大吗?我们知道,Gemini 此次有三个版本,能力最强的 Gemini Ultra、多任务的 Gemini Pro、以及特定任务和端侧的 Gemini Nano。
目前,谷歌类 ChatGPT 应用 Bard 可免费升级到 Gemini Pro 版本,Gemini Ultra 预计于明年初通过 Bard Advanced 与用户见面。

在与 GPT-4 的比较中,谷歌给出的数据是 Gemini Ultra 全面超越 GPT-4,Pro 在大多数指标上超越 GPT-3.5。

但实际效果究竟如何呢?推特用户 Brett Winton 首次对 Gemini Pro、Claude 和 GPT-3.5 进行了基准测试,对每个模型提了一道 8 年级的故事题。他得出的结论是:GPT-3.5 满分、Claude 约 67 分,Gemini Pro 完全没有那个味。
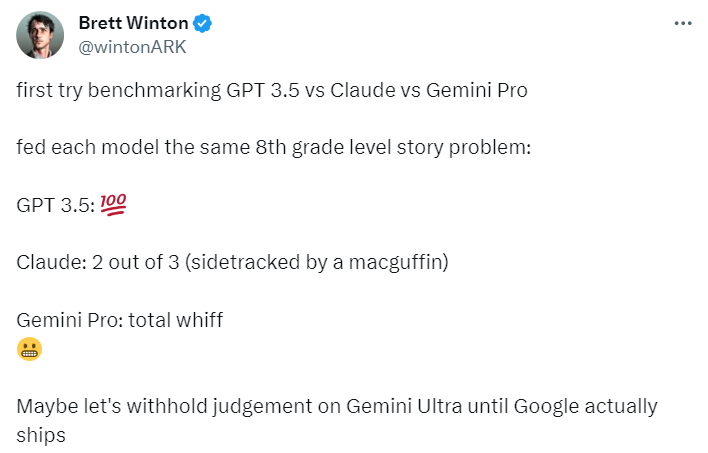

图源:https://twitter.com/wintonARK/status/1732527909376815419
三个模型给出的答案分别如下:

从左到右依次为 Bard(Gemini Pro)、Claude 和 GPT-3.5。
看到这一结果,似乎只能用「升级了,但还没完全升级」来做解释。他表示在 Gemini Ultra 最终上线之前,还是不对它的能力做评价了。
Gemini 开创了新架构,引来了流量,也遭受了批评,那么现在看来,谷歌反攻微软的大计成了没成?
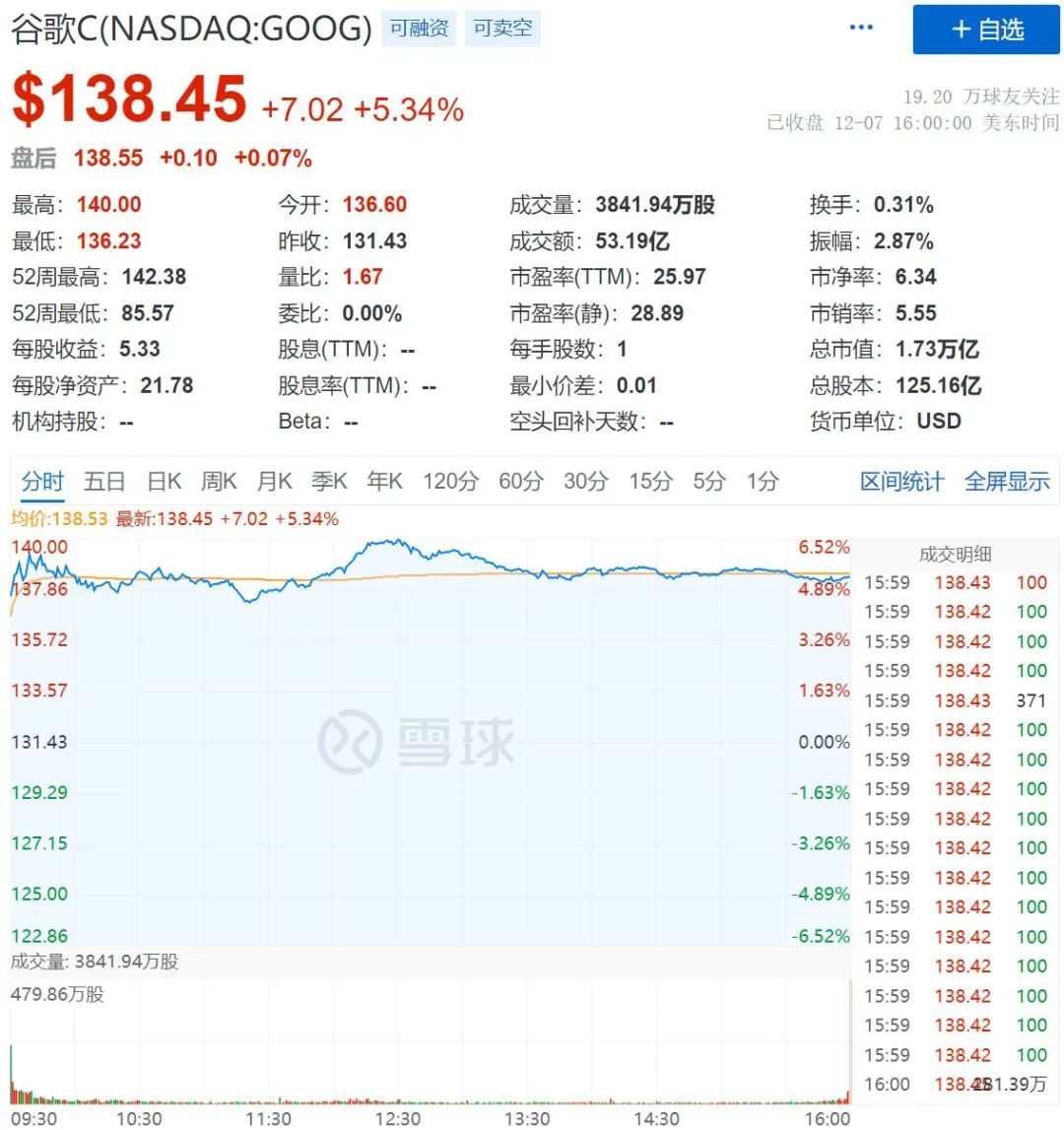
至少从投资者们来看是个好的开头。
本周四,谷歌的股价经历了暴涨,市值增加了 800 亿美元。需要记得的是,在 2 月份谷歌推出 Bard 时,谷歌的股价一天跌去了 1000 亿美元。
人们认为,Gemini 可以帮助谷歌缩小与微软、OpenAI 在大模型上的差距。
也许 1.0 版的 Gemini 只是开了个头,我们还要保持耐心,等待大模型的进一步技术升级。
尽管网友对谷歌Gemini当前的表现存疑,但在研究人员看来,谷歌Gemini不必与GPT比参数,它的价值在于“原生多模态”。
“原生多模态”是指将不同模态的信息(如视觉、听觉、语言等)进行融合,通过多种媒体形式进行表达和传递。在现实世界中,人们接收和理解信息的方式往往是多模态的,通过同时获取不同感官的输入,融合多种信息来源来构建对世界的认知。

参考链接:
https://mp.weixin.qq.com/s/TVO2Z-6vlCkE-ZmUeP_0uA https://mp.weixin.qq.com/s/LPUhiX2nsK9QQHVfIefOUA https://mp.weixin.qq.com/s/yboP5fZ9CoPGz_AhTLS9Aw https://mp.weixin.qq.com/s/83tIh_95Kx-_R6t3YlGHrw
END

点这里↓↓↓记得关注标星哦~
中智凯灵中智凯灵(KeyLink)是国内领先的专业数字人才发展平台,面向科技研发型企业和组织提供数字化人才培养的专属成长地图,数字化转型的方法 + 智库。105篇原创内容公众号

AI9AI · 目录上一篇
北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

