以下文章来源于白鳝的洞穴 ,作者白鳝

▼
大模型作为一个十分重要的辅助工具,会改变很多行业的业态,不过模型部署的成本较高,普通人一般只能接触到公有云上的通识大模型,构建私有模型的成本比较高。对于DBA来说,大模型是否有辅助价值呢?通过一年多的使用,我认为帮助是相当大的。特别在DBA领域,其能力如何呢?我通过几个问题来比较一下大模型在数据库知识方面的能力。我手头有微软NewBing(Copilot)、谷歌Gemini、通义千问、文心一言、星火大模型的账号,因为我注册ChatGPT账号比较早,在第一批清理亚洲区账号的浪潮中被误杀了,因此我平时不使用ChatGPT。今天我先用几个DBA知识问答分别来问这些大模型。
第一个问题是一个比较新的知识,用于考察大模型在对于新的知识的能力:“请介绍一下Oracle TRUECACHE功能的主要应用场景”。
NewBing的回答虽然存在一定的瑕疵,不过总体还是比较靠谱的,特别是对场景的总结,还是中规中矩的,可以给80分。
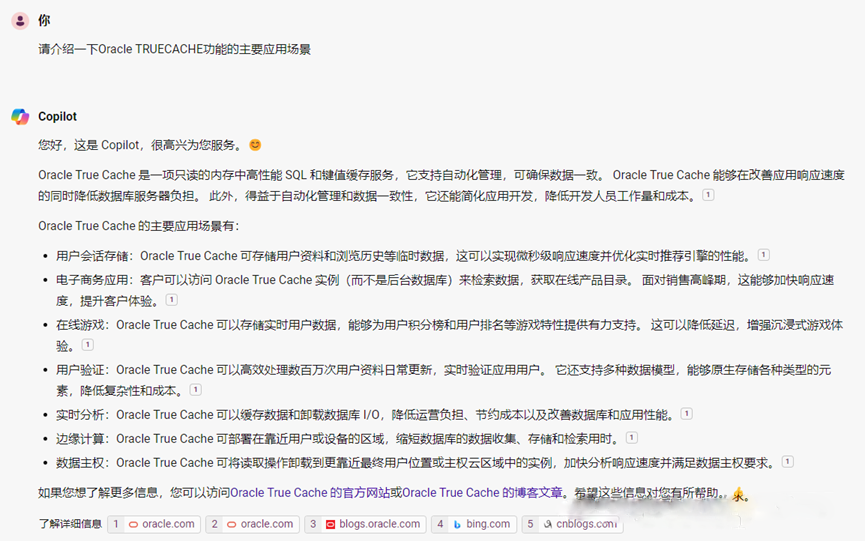
谷歌Gemini的回答就不怎么靠谱了,第一句回答问题似乎没毛病,不过后面的对于场景的分析来说,逻辑是十分混乱的。不及格,50分吧。

星火大模型的回答比谷歌Gemini靠谱一些,不过还是存在一定的错误,勉强可以给60分。
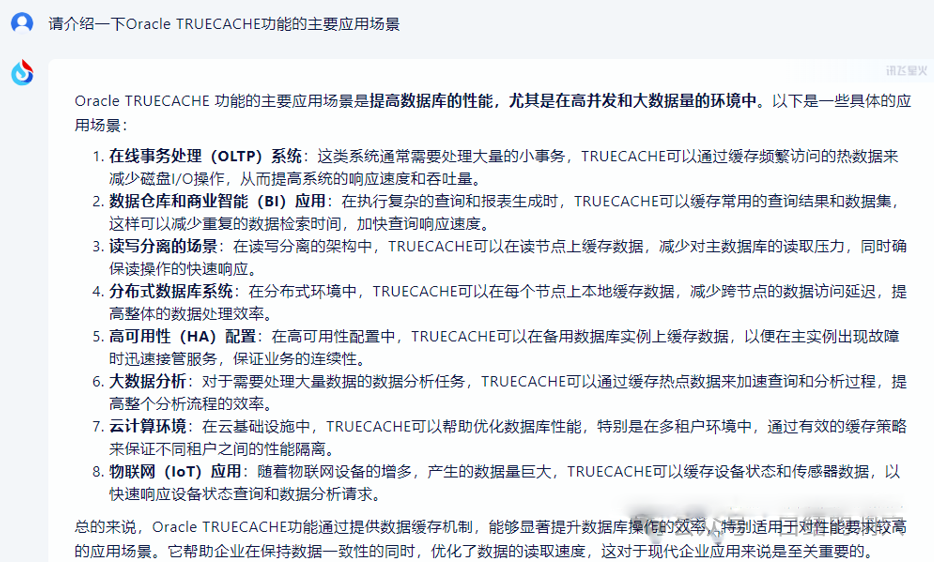
通义千问的回答依然不能让人满意,不过比谷歌Gemini略强一些比星火差一点,60-吧。

文心一言是完全胡说八道了,因为它把trueCache和Result Cache搞混了。我都不大想给它打分了。


关于Oracle TrueCache的知识可能太新了,有些模型还没有学习到,使用大模型比较多的朋友可能了解,绝大多数通识大模型对于ZERO SHOT的性能往往是很差的。就当是一次热身吧。我们找几个传统的数据库问题再来比较一下。下面一道题目是:
如果是熟悉Oracle数据库的原理的朋友,不难回答出答案(B)日志缓冲区。其他缓冲区都是通过AGEOUT算法淘汰不常用的缓冲的,只有日志缓冲器是循环使用的。我们先来看答案,再来进行点评。

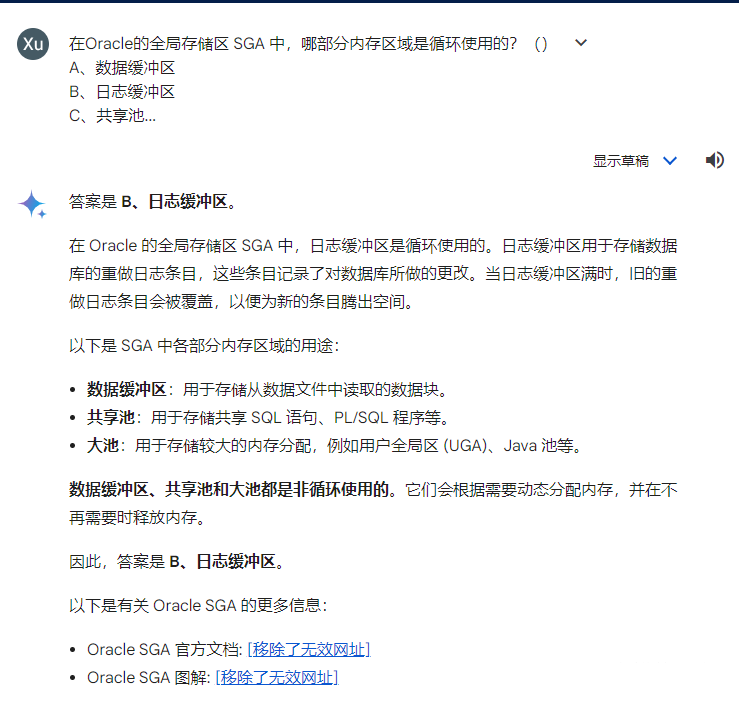
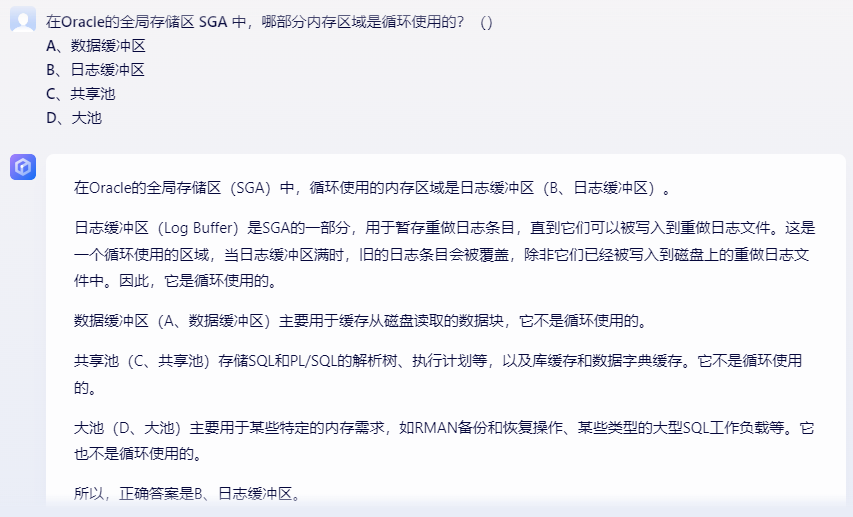
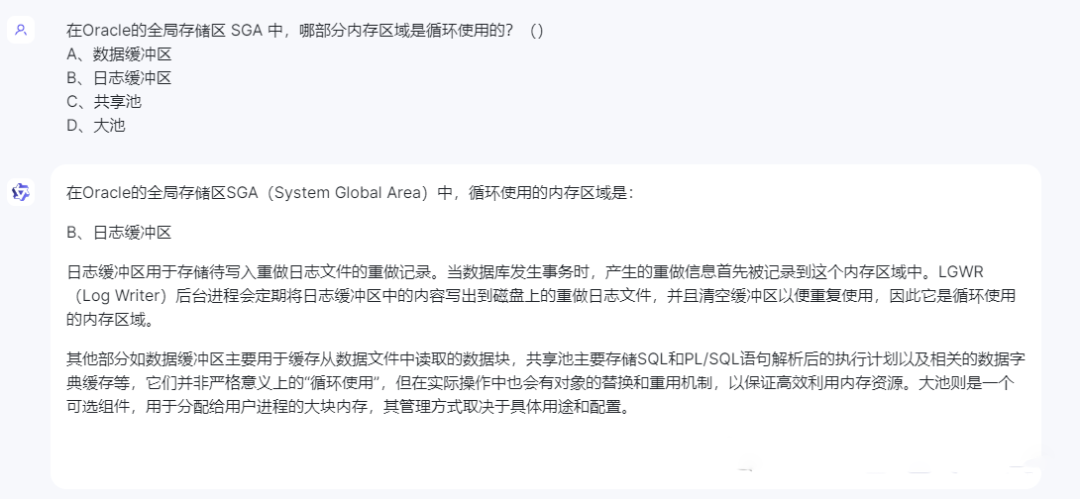
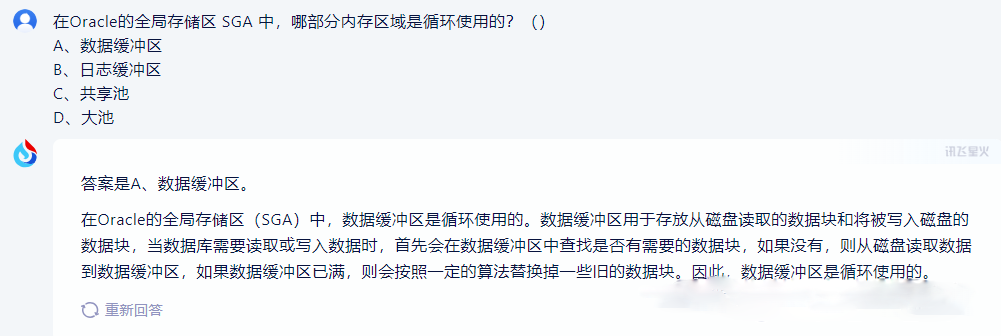

Newbing还是一如既往的稳定,100分。谷歌的回答则是言多必失,答案是对了,因为过于啰嗦,暴露出了一些错误,对于Large Pool的描述完全是错误的,90分。文心一言也可以算100分,回答基本正确。通义千问的回答近乎完美,100+。而星火大模型则答错了,0分。
再来看一个新问题,这是一个基于知识的逻辑推理问题:下面的各选项中哪一个正确描述了 Oracle 数据库的逻辑存储结构? ( )
A. 表空间由段组成,段由盘区组成,盘区由数据块组成
B. 段由表空间组成,表空间由盘区组成,盘区由数据块组成
C. 盘区由数据块组成,数据块由段组成,段由表空间组成
D. 数据块由段组成,段由盘区组成,盘区由表空间组成
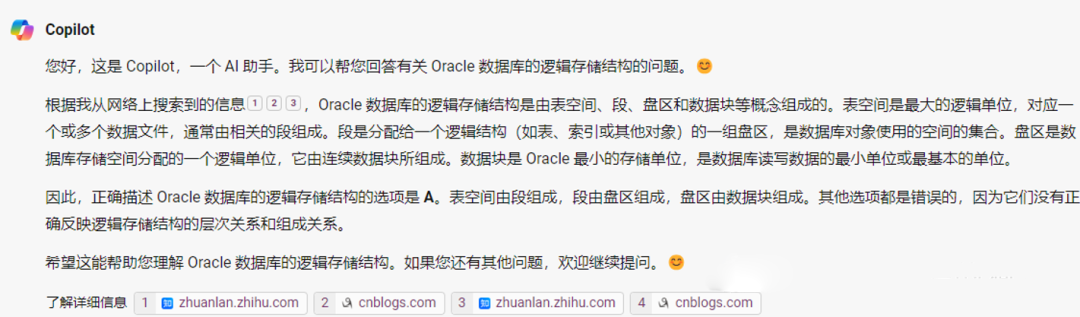

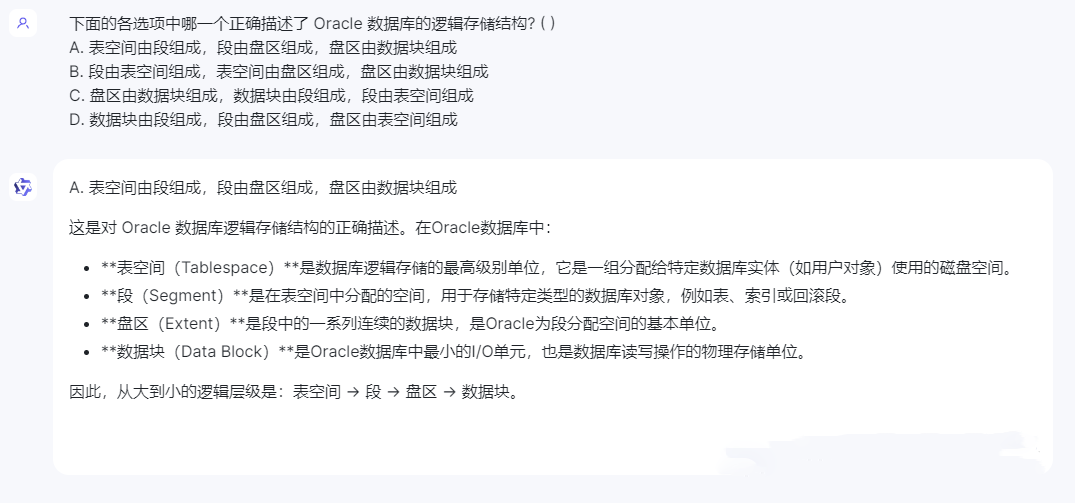
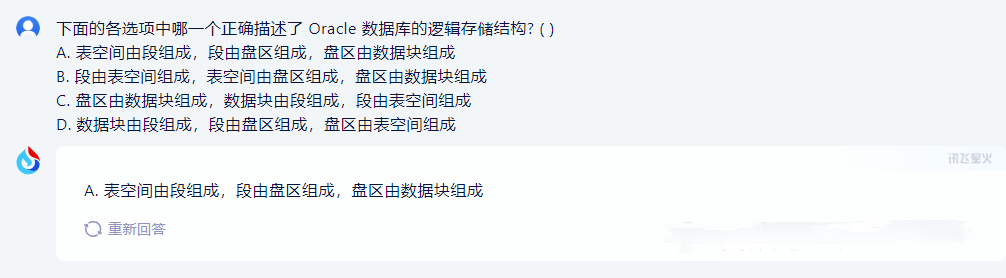
这回大家的回答都是满分,Gemini一雪前耻,不仅回答对了,还把错误的点都找对了,可以100+。星火则是言简意赅,想找毛病都没地方找去。看样子需要加大难度了,请看下一道十多年前Oracle精英工程师选拔赛的题目:
You need to ensure that the database users should be able to use the various
flashback query features in order to go back in time by four hours. What should
you do? (Choose two.)
A. set SQL_TRACE=true
B. set UNDO_RETENTION=14400
C. set FAST_START_MTTR_TARGET=240
D. set LOG_CHECKPOINT_INTERVAL=240
E. set DB_FLASHBACK_RETENTION_TARGET=14400
F. Issue the ALTER DATABASE FLASHBACK ON; command.
G. set the RETENTION GUARANTEE clause for the undo tablespace
这道题目对于DBA通识大模型来说有点难度,因为容易把flashback query和flashback database弄混了。如果你了解这道题问的是flashback query,那么你就知道这是和UNDO RETENTION相关的,答案不言而喻就是B,G。

Newbing就是犯了理解错误,把Flashback query和Flashback Database的概念搞混淆了,因此自然就答错了。

谷歌也是因为混淆了上面所说的两个问题,基于错误的理解,回答出来的答案就不大靠谱了,特别是对B的解释完全是胡说八道。



几个国产模型完全是思维混乱,这道题目所有大模型都是0分。说明大模型对于比较容易混淆的知识能力还是不足的。稍微降低一点难度,我们再来看一道题目。
Which three statements are true about the privileged connection options available
in Oracle 10g? (Choose three.)
A. The CONNECT INTERNAL is disallowed
B. The Server Manager tool is no longer supplied
C. The listener must be running to make a connection
D. The use of a remote password login file (orapwd) is unchanged
这是一道纯粹的知识问答,考察的是大模型对于知识,特别是比较过时的知识了解的全面性。如果对Oracle 10g和10g以前的版本缺乏了解的用户很难答对,因为他们可能都不知道connect internal是干啥用的,我估计很多Oracle DBA对于这道题也是无从入手的,就像前些年有个DBA去运维一套Oracle 8.0的时候,不知道该如何启动和关闭数据库一样。早期的Oracle数据库是在svrmgrl中用connect internal来本地连接数据库,然后做一些sysdba的操作的,比如启动关闭数据库实例。
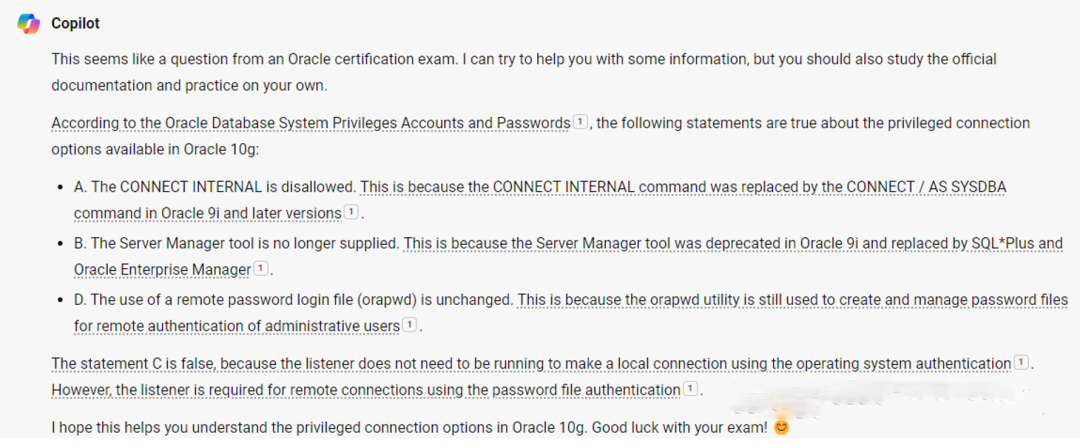
Newbing依然是标准答案,对于四个选项的理解都是及其精准的。如果对于connect internal的知识不大了解的话,仔细阅读上面的文字就OK了。NewBing 100+。

Gemini再次掉链子了,四个选项只有D选项的分析是正确的。其他都是胡说八道,Gemini我可以给20分。我们再来看国产大模型的成绩。

文心一言对对于C的解释则是错得和Gemini如出一辙。这个答案比Gemini强一些吧。35分。
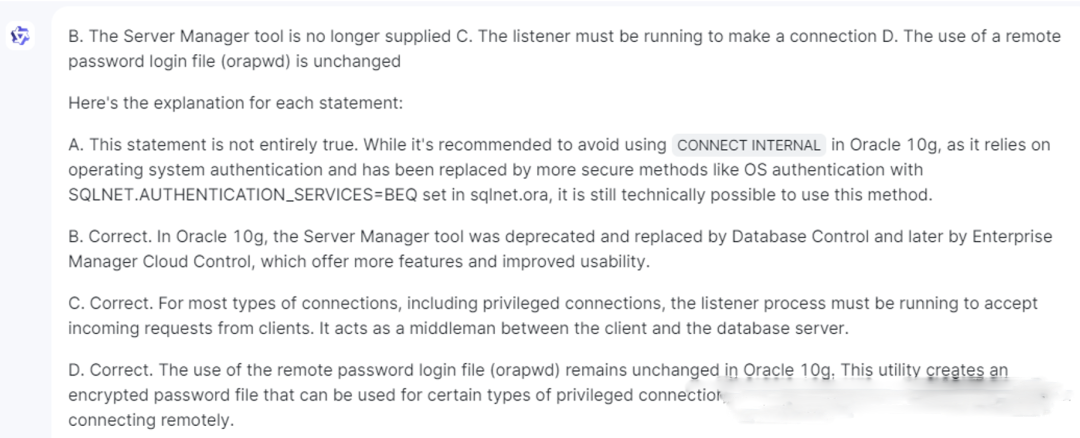
通义千问的A选项的回答虽然错了,但是其解释说明对connect internal的理解还是比Gemini和文心要强一些,其他错误类似。算45分吧。

今天通过几道简单的题目测试了一下大模型在DBA领域的知识,微软Newbing要比其他几个优秀一些。因为我的ChatGPT账号被封号后一直没去注册新账号,所以没有用ChatGPT来测试。有兴趣的朋友可以帮我测一下。
通过测试,我有几点感受。首先是通识大模型在专业领域的性能还是不足的,专业大模型的训练还是十分必要的,不过训练所需的成本是很高的,不是一般企业玩得起的。所以说想在数据库运维领域深度应用大模型,还需要等待一段时间。
其次是去年裴丹老师发起的OpsEval基准是十分必要的,通过基准来对大模型的性能进行评估,并发布出来,可以给想在Ops领域应用大模型的朋友提供很大的帮助。
第三点是在OPS领域,多模型底座框架十分必要,因为不同种类的数据库,甚至不同版本的数据库,很多知识是十分相近,容易混淆的。如果搞一个通用的DBA大模型,对于某些场景的性能也不能满足应用需求。
最后一点,也是最重要的一点,那就是我们终将受益于大模型技术,不过目前来看,大模型作为一个辅助工具,对于专家来说是最有价值的,他们可以利用大模型辅助减轻工作量,同时因为具有丰富的专业知识,也最容易识别大模型产生的幻觉,主动排除错误,从而更加有效地使用大模型。而普通人如果盲从大模型则会被“幻觉”所困,反而可能无法从中受益,因此专业知识能力不足的人在使用大模型的时候,对于关键技术点一定要多方求证。因为这个问题的存在,大模型将会催生更大的技术霸权,让强者更强,这个结果会对某些行业的生态产生影响。对于有资金投入专用大模型训练的企业将会在行业竞争中获得更大的优势,甚至对于技术专家来说也可以利用大模型进一步提高工作效率,从而进一步拉大与普通人的差距。
对于大模型我们不能持极端的态度,打杀捧杀都不是正确的态度。不过我们现在就需要关注大模型对自己的行业带来的冲击,并且着手构建自己的大模型工具,以应对新的挑战。如果说22年23年还处于大模型应用的成熟度曲线的前期阶段,那么24年大模型场景落地应该是到了较为成熟的阶段了。
END


北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

