
当整个行业还在为谁的Token消耗更多争得面红耳赤时,真正决定AI胜负的战场,早已转移到了你看不见的地方。
2026年的春天,AI行业正陷入一场诡异的"指标焦虑"。
打开任何一家大模型的官网,"累计生成XX万亿Token"的标语几乎成了标配。投资人的路演PPT里,Token增长率被当作核心KPI反复强调。媒体头条争相报道"某模型日活突破千万,Token消耗量环比增长300%"。
仿佛只要数字足够大,商业价值就会自动涌现。
但就在上周,全球权威研究机构Gartner抛出了一记重锤:Token消耗是衡量AI市场领导力的误导性指标。
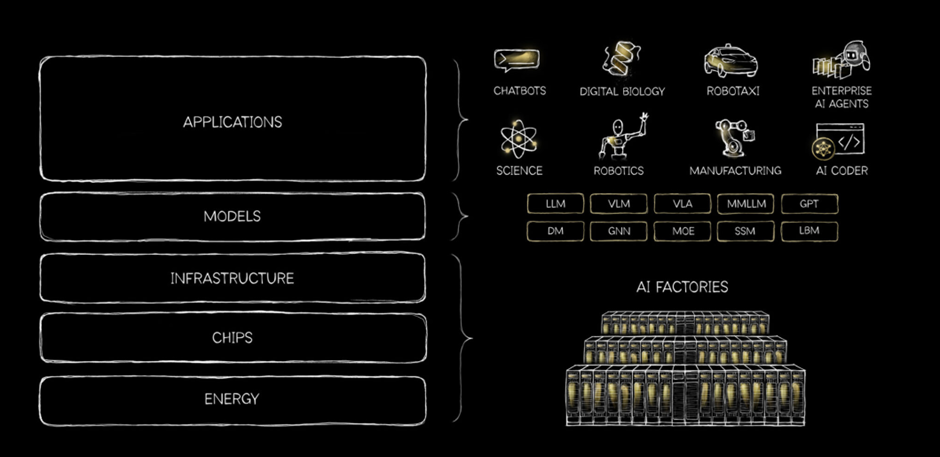
几乎同一时间,英伟达创始人黄仁勋罕见以个人名义发表长文,提出了一个更底层的框架——"AI五层蛋糕"理论:能源→芯片→基础设施→模型→应用。
这两件事放在一起看,意味深长。
当行业还在用"表层指标"互相攀比时,真正的玩家已经在重构整个技术栈的底层逻辑。
今天,我们不聊情怀,不谈愿景,就用最硬核的数据和最尖锐的视角,拆解这场正在发生的范式转移。
先说结论:把Token消耗当作成功指标,就像用"汽车发动机转速"来衡量一次旅行的价值。
转速可以很高,但车可能一直在原地空转。
根据Gartner的深度分析,Token指标存在三个结构性问题:
第一,技术上无法横向比较。
不同模型的Token定义、分词策略、上下文窗口设计完全不同。同样是"100万Token",在模型A那里可能是10万字,在模型B那里可能只有3万字。更关键的是,有些模型通过"思维链"(Chain-of-Thought)生成大量中间推理步骤,这些"过程性Token"是否应该计入"有效消耗"?
行业目前没有任何统一标准。
第二,与业务价值严重脱节。
一个客服机器人每天消耗1亿Token,但解决的客户问题转化率只有0.3%;另一个系统每天只消耗100万Token,但直接促成百万级订单。哪个更有价值?
答案显而易见。但资本市场往往更青睐前者,因为"数字好看"。
第三,激励错位,催生"刷量经济"。
当考核指标是Token消耗时,厂商的最优策略是什么?
这就像短视频时代的"完播率作弊"——数据漂亮了,但用户体验和商业效率反而下降。
中国市场的情况更为复杂。
激进的免费策略、平台级AI整合、面向消费者规模的部署,共同推动了Token消耗的指数级增长。但问题在于:消耗量≠付费意愿≠商业闭环。
某头部大模型厂商曾公开表示,其日均Token消耗量已突破千亿级别。但同期财报显示,AI相关业务的营收占比仍不足5%,且毛利率持续承压。
这不是个案,而是行业普遍现象。
更值得警惕的是,当企业把"低成本获取用户"等同于"建立竞争壁垒"时,很容易陷入"烧钱换规模,规模换估值,估值换融资"的循环。一旦资本退潮,整个模式将面临严峻考验。
Gartner给出了四个更可靠的评估维度:

一句话总结:从"活动指标"转向"结果指标"。
如果说Gartner是在"破",那么黄仁勋的长文就是在"立"。
这篇题为《AI is a 5-Layer Cake》的文章,看似简单,实则信息密度极高。它不是在讲产品,而是在讲产业范式;不是在谈技术细节,而是在谈系统架构。
理解"五层蛋糕"的前提,是先理解AI带来的范式革命。
在传统计算时代,软件是"预编写"的:人类设计算法→计算机执行→数据结构化存储→通过SQL精确查询。这是一个"确定性"的世界。
而AI打破了这个模式。
"第一次,我们拥有了一种能够理解非结构化信息的计算机。它可以看图像、读文本、听声音,并理解其中的含义。它能够根据上下文和意图进行推理。最重要的是,它能够实时生成智能。"
这意味着什么?
这种转变,直接导致整个计算技术栈必须被重新发明。
"每生成一个词元(token),本质上都是电子在流动、热量在被管理、能量在被转化为计算。在这之下没有任何抽象层。"
这句话值得反复咀嚼。
在软件时代,我们习惯了"抽象层"的便利:写代码不用管晶体管怎么开关,训练模型不用管GPU怎么散热。但到了AI时代,能源成了无法绕过的硬约束。
几个关键数据:
这意味着:谁掌握了高效、稳定、低成本的能源供给,谁就掌握了AI时代的"入场券"。
这也是为什么微软、谷歌、亚马逊都在疯狂布局核电、可再生能源、液冷技术。这不是"锦上添花",而是"生死攸关"。
芯片层的逻辑很清晰:把能源高效转化为计算能力。
但难点在于,AI工作负载对芯片提出了全新要求:
巨大的并行计算能力:传统CPU的串行架构无法胜任
高带宽内存:模型参数动辄数百GB,内存带宽成为瓶颈
高速互连网络:万卡集群协同,通信延迟直接影响训练效率
英伟达的护城河,本质上就是在这三个维度上建立了系统性优势。而国产芯片的追赶,也必须从这些"硬指标"入手,而不是简单比拼"算力峰值"。
更关键的是:芯片层的进步,直接决定了智能的"边际成本"。
当单次推理成本从1美元降到0.01美元,商业模式的想象空间将完全不一样。
"这些系统本质上是AI工厂。它们并不是为了存储信息而设计的,而是为了制造智能。"
这个比喻极其精准。
传统数据中心是"仓库",核心能力是存储和检索;而AI基础设施是"工厂",核心能力是"生产智能"。
这意味着基础设施的设计逻辑必须重构:
传统数据中心 | AI工厂 |
|---|---|
高可用、低延迟 | 高吞吐、可扩展 |
通用计算资源 | 专用AI加速集群 |
网络拓扑相对简单 | 万卡级互联,通信优化至关重要 |
运维以"稳定"为核心 | 运维以"效率"为核心 |
黄仁勋提到,全球范围内正在以前所未有的规模建设"芯片工厂、计算机组装工厂、AI工厂"。这可能会成为人类历史上最大规模的基础设施建设之一。
注意,不是'之一',而是真正的'头号工程'。
"语言模型只是其中的一类。一些最具变革性的进展正在发生在:蛋白质AI、化学AI、物理仿真、机器人技术、自动化系统。"
这句话,可能是整篇文章最容易被低估的部分。
当前行业对模型的关注,过度集中在"大语言模型"上。但黄仁勋明确指出:模型的本质是"理解世界",而语言只是世界的一种表达方式。
几个正在爆发的方向:
科学智能(AI for Science):AlphaFold3、药物发现、材料设计
具身智能(Embodied AI):机器人、自动驾驶、工业控制
多模态融合:视觉+语言+动作的端到端理解
这些领域的突破,往往比"聊天更聪明"带来更大的商业价值。
"一辆自动驾驶汽车,是具象化在机器中的AI应用。一个人形机器人,是具象化在身体中的AI应用。技术栈相同,结果不同。"
应用层的核心逻辑:把底层能力转化为可感知的用户价值。
但难点在于,应用不是"套个壳"那么简单。它需要:
这也是为什么,同样调用同一个大模型,有的产品日活百万,有的却无人问津。
黄仁勋特别强调了一个关键洞察:
"每一个成功的应用,都会向下牵引整个技术栈,一直延伸到为它提供电力的发电厂。"
这意味着什么?
工业机器人的落地,会要求基础设施提供更低的延迟和更高的可靠性
应用不是技术栈的"终点",而是"起点"。
这也解释了为什么开源模型如此重要:当强大的推理模型变得广泛可用,它不仅加速了应用层创新,更激活了整个技术栈的需求。
DeepSeek-R1就是一个典型案例:通过提供免费的强推理模型,它既降低了应用开发门槛,又间接拉动了对训练算力、基础设施、芯片和能源的需求。
基于Gartner和黄仁勋的洞察,我们提出一个"四层价值漏斗"框架:
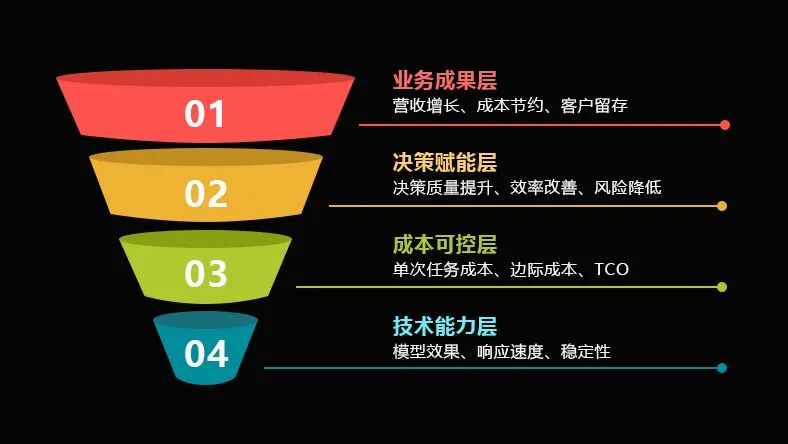
关键原则:越往上,权重越高。
很多企业在选型时,过度关注"技术能力层"的指标(如准确率、响应时间),却忽视了"业务成果层"的验证。结果就是:技术指标很漂亮,商业价值很骨感。
对于希望系统性布局AI的企业,建议从三个维度构建能力:
① 战略层:明确"智能"在业务中的定位
定位不同,资源投入和技术路径完全不同。
② 技术层:构建"可组合"的AI能力中台
避免"烟囱式"建设,建议采用"能力中台+场景应用"的架构:
这样既能保证技术复用,又能快速响应业务需求。
③ 组织层:建立"业务+技术"的协同机制
AI项目失败的最大原因,往往不是技术不行,而是"业务不懂技术,技术不懂业务"。
建议设立"AI产品经理"角色,既懂业务痛点,又懂技术边界,成为双方的"翻译官"和"连接器"。
陷阱一:盲目追求"大模型"
不是所有场景都需要千亿参数。很多时候,一个经过精细微调的中小模型,效果反而更好、成本更低、响应更快。
陷阱二:忽视数据治理
"垃圾进,垃圾出"。没有高质量、结构化、合规的数据,再强的模型也发挥不出价值。
陷阱三:低估合规成本
尤其是在金融、医疗、政务等强监管领域,数据安全、隐私保护、算法可解释性等要求,可能成为项目落地的"最后一公里"障碍。
2026年,可能是AI行业的"分水岭之年"。
过去三年,我们见证了技术的爆发、资本的狂热、用户的期待。但接下来,行业将从"讲故事"进入"交答卷"的阶段。
谁能在"五层蛋糕"的每一层都建立扎实能力,谁就能穿越周期。
这些问题,没有标准答案。但可以确定的是:继续用Token消耗来"自嗨"的玩家,正在被时代悄悄淘汰。
黄仁勋在文末写道:
"我们仍然处在早期阶段:许多基础设施尚未存在,许多劳动力尚未完成培训,许多机会尚未被实现。但方向已经非常清晰。"
方向清晰,路径艰难。
对于真正想在这个时代留下印记的企业和个人来说,现在不是焦虑的时候,而是沉下心来、回归本质、扎实建设的时候。
因为最终决定AI胜负的,从来不是"谁的声音更大",而是"谁的价值更实"。
共勉。
本文观点基于公开资料分析,不构成任何投资建议。行业变化迅速,请以最新信息为准。
参考资料:
1. Gartner《Token消耗是衡量AI市场领导力的误导性指标》
2. 黄仁勋《AI is a 5-Layer Cake》(英伟达官方博客)
3. 长江商学院编译版及相关行业研报
推荐活动
备受赞誉的AiDD峰会组委会和K+峰会组委会联合发起的“AI+产品创新峰会”,即将于2026年4月10-11日在上海举办,峰会旨在以AI为引擎,以产品为载体,打通从技术创新到商业落地的全链路 ,探索“AI+产品”的融合范式,形成从战略思考到技术实现,从产品创新到商业成功的完整闭环。

#第9届AiDD峰会议题征集通道开启,欢迎诸位大咖提交议题,共启AI引领研发新征程,一同重塑研发DNA,定义未来无限可能!

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

