
陆家靖——2020年博士毕业于复旦大学,在学期间得到国家留学基金委资助,赴意大利国家核物理研究院联合培养。开源爱好者,Apache、Skywalking、Committe、Skywalking-BanyanDB主要贡献者。目前就职于上海收钱吧,主要负责APM系统的开发。
▼
— 1 —
引言
随着分布式系统和微服务的日益发展,系统的开发和运维对于可观测性的需求越来越迫切。可观测性[1]一词的来源最初是从控制理论中借鉴而来的。目前我们在谈论可观测性的时候,我们通常是指以下三个方面:
链路 Tracing
指标 Metrics
日志 Logging
这三者并不完全是三个独立的概念,而是相辅相成的。谈及这三个方面,我们总是不得不提及Peter Bourgon的文章[2],以及其中最经典的Venn diagram:
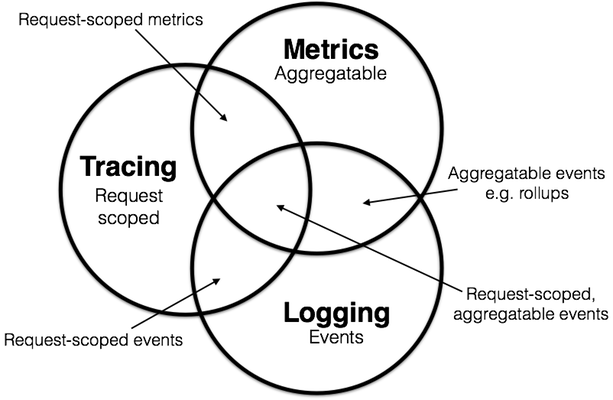
— 2 —
收钱吧监控系统的历史发展
收钱吧从在2017年开始逐步建设应用监控系统,系统建设主要的方向是提供链路追踪(Tracing)以及性能监控(Metrics)两方面的能力。
在监控系统的选型方面,我们尽量使用开源的系统:
在接入层,我们采用最原始的方式,为各个Java的模块、组件提供各种各样的instrumentation工具包来进行埋点,业务研发同学以pom依赖的形式引用到自己的业务服务中,比如:
这套系统支撑我们走过了业务发展最迅猛的一段时间,为大量的问题排查和故障诊断提供了一些线索,然而业务开发逐渐开始对这套系统产生不满,主要集中在以下几个方面:
由于我们在初期采用MySQL作为底层时序数据的存储,这在当时看起来是一个主流的方案[6],但我们碰到了很大的性能问题,毕竟MySQL这类数据库提供的存储引擎并没有对此类场景进行优化[7]。同时,MySQL并没有提供丰富的针对时间序列的查询算子。
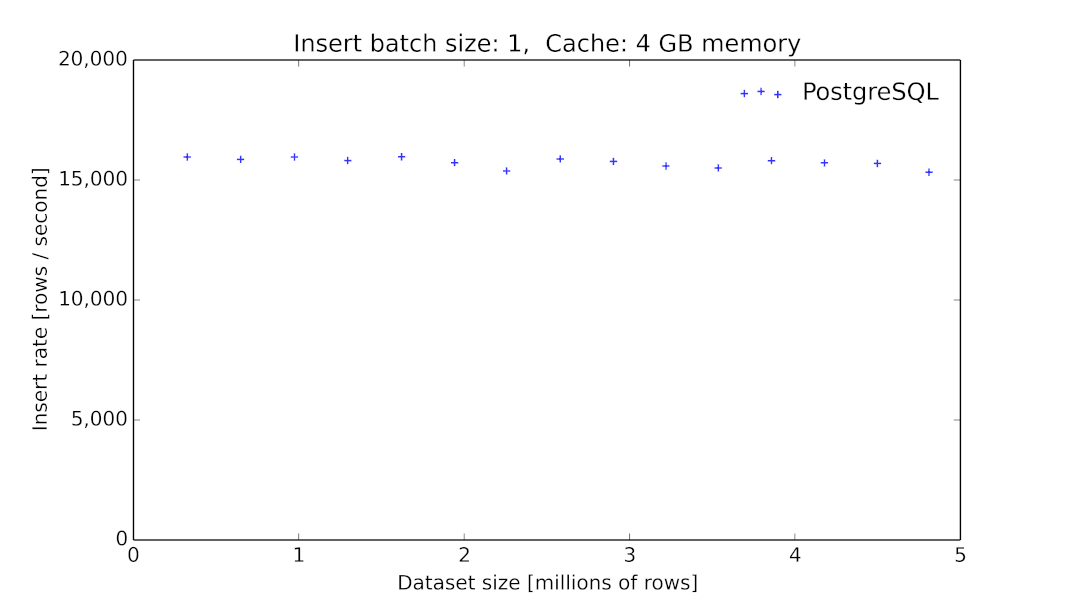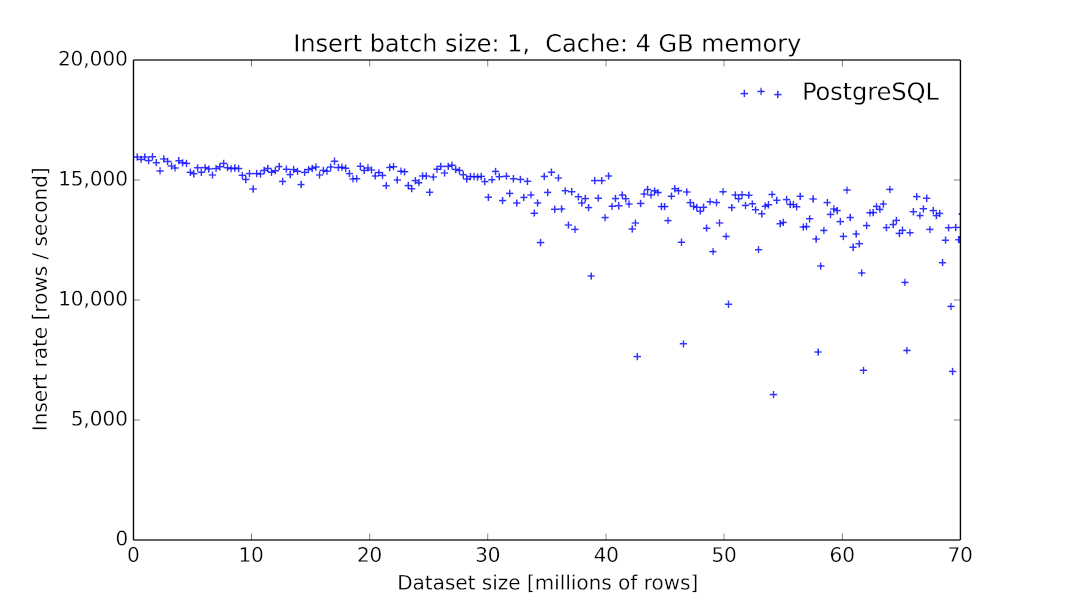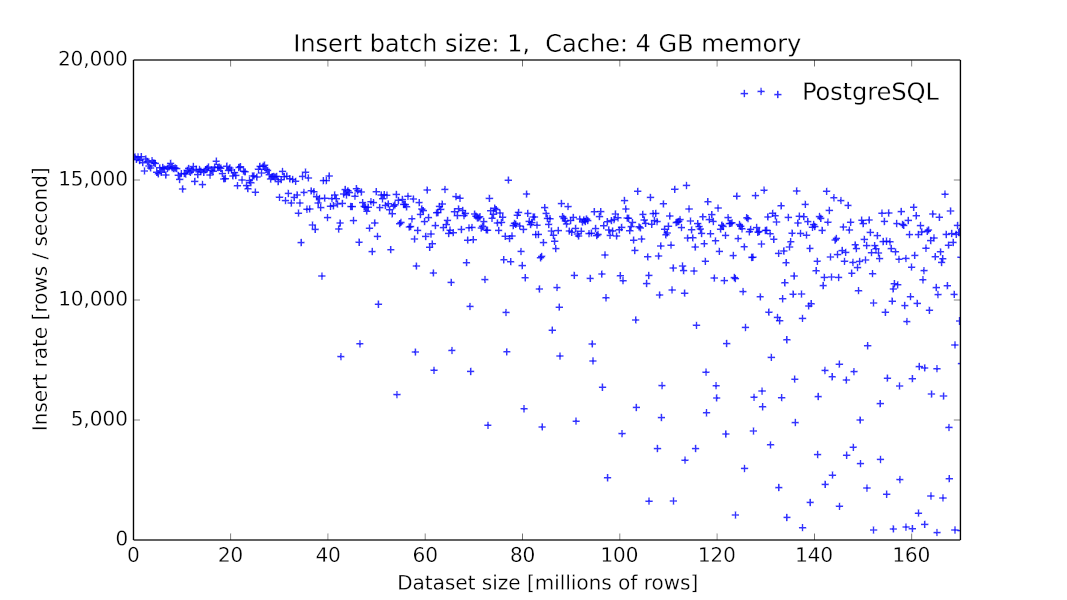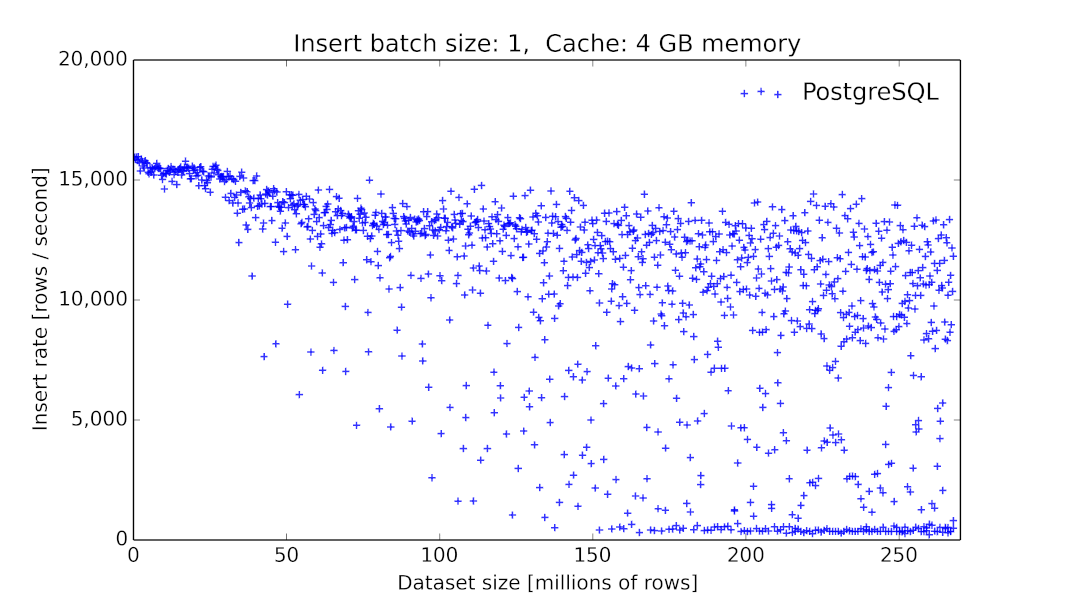
PgSQL 9.6.2 数据插入的吞吐量随着表大小的变化关系[8]
在链路追踪或者说应用监控的场景,我们需要的是高吞吐量以及线性的性能[9],同时我们也需要增加数据的生命周期管理的功能:因为随着新数据的写入,历史数据的价值会随着时间的流逝而价值降低。
2. 由于我们需要从Tracing数据反推得到指标数据Metrics,我们“魔改“了Zipkin传输部分的逻辑,对所有不采样数据(Unsampled)在客户端进行聚合以后批量上报,导致我们在Zipkin的升级方面产生了很大的困难。尤其是在https://github.com/openzipkin/zipkin/pull/1968,以后不再允许用户定制开发服务端。
3. 业务方升级依赖需要采集器组件升级支持,从而产生了额外的工作量。同时,也有大量的组件难以通过这种侵入性的方式进行支持,或者需要投入很大的人力成本来进行研发、适配。
— 3 —
新一代应用监控系统 - Hera
基于以上原因,我们决定研发一套新的系统来同时满足几个条件:
分布式链路追踪的概念和心智模型(Mental Model)大多是受到2010年发表的Google’s Dapper论文[10]的影响。在Dapper论文中,作者明确地指出了Trace的树形结构,
We tend to think of a Dapper trace as a tree of nested RPCs.
以及提出了所谓Span的概念,
In a Dapper trace tree, the tree nodes are basic units of work which we refer to as spans. The edges indicate a casual relationship between a span and its parent span.
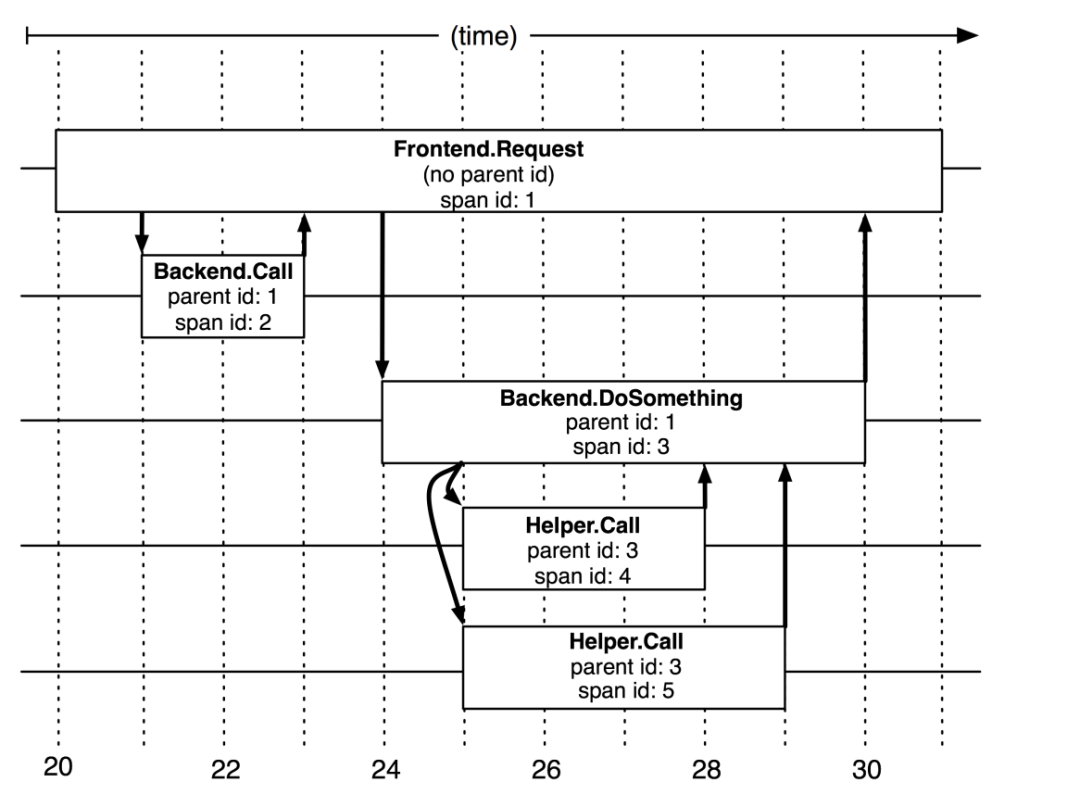
在一个Dapper链路树中,各个Span之间存在因果和时序关系。
在链路追踪的系统选型方面,我们对比了在当时比较活跃的几个开源项目,
Jaeger是Uber[11]在2016年开源的链路追踪平台,并捐献给了CNCF云原生基金会。
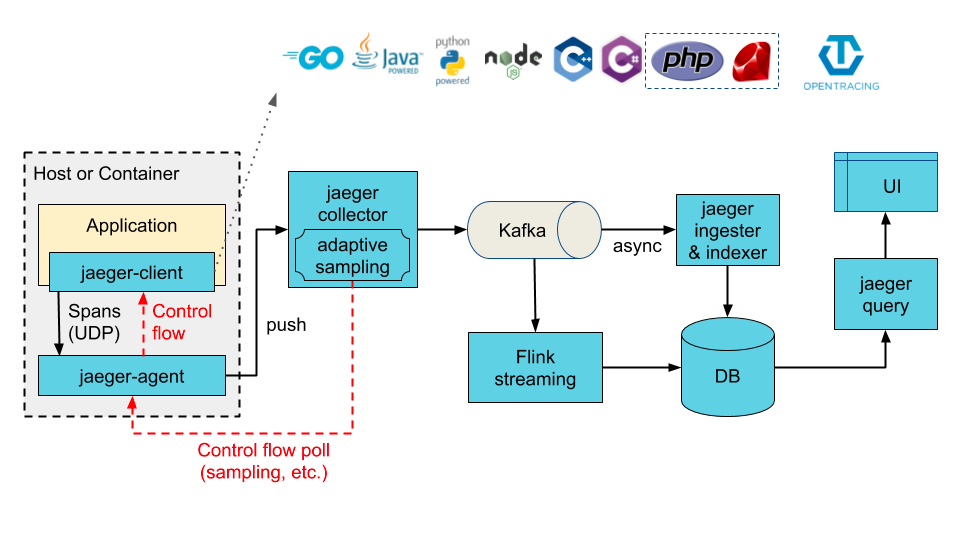
Jaeger的主要组件和控制流、数据流示意图,其中使用Kafka作为缓冲管道。
Jaeger受到了开源社区的广泛支持,比如
链路追踪后端系统和存储的选型
我们重点考虑的是他们对于存储系统方面的支持情况和扩展能力,
各个开源链路追踪实现的存储能力
| Product | Storage provided officially | Community supported |
|---|---|---|
| Zipkin | In-memory, MySQL, Cassandira, Elasticserach, AWS X-Ray, GCP Stackdirver | Logz.io, Scouter APM, Apache Kafka |
| Jaeger | In-memory, Cassandira 3.4+, Elasticsearch 5.x 6.x, Kafka, gRPC Plugin | Additional storage backends, InfluxDB via grpc-plugin, Logz.io, ScyllaDB |
| Skywalking | H2(In-memory), Elasticsearch 6.X 7.X, MySQL, TiDB |
Jaeger社区对于存储的扩展性极佳,提供了基于gRPC的插件机制[14],方便定制扩展,
parent process child sub-process
在存储的具体选择方面,我们在当时注意到了Aliyun SLS能够支持作为链路追踪的后端,并且官方提供了一个实现https://github.com/aliyun/aliyun-log-jaeger,我们内部基于这个思路实现了gRPC插件版本的SLS后端实现,目前稳定运行在生产环境,

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

