
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat
一个快速、负担得起、可扩展和开放的系统框架,用于实现端到端强化学习人类反馈 (RLHF) 培训体验,以生成各种规模的高质量 ChatGPT 样式模型。

目录



https://github.com/databrickslabs/dolly
https://github.com/OptimalScale/LMFlow
https://github.com/CarperAI/trlx
https://github.com/huggingface/peft
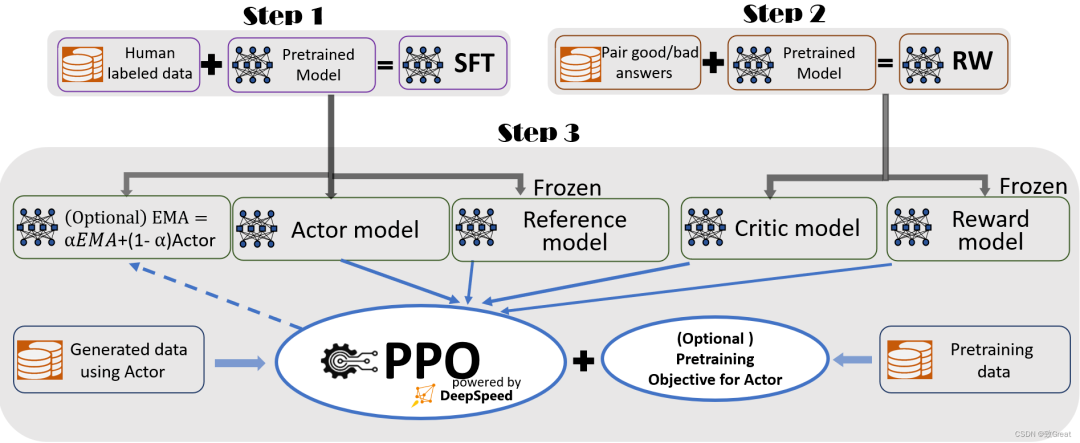
DeepSpeed Chat 特性
快速上手




科技改变生活
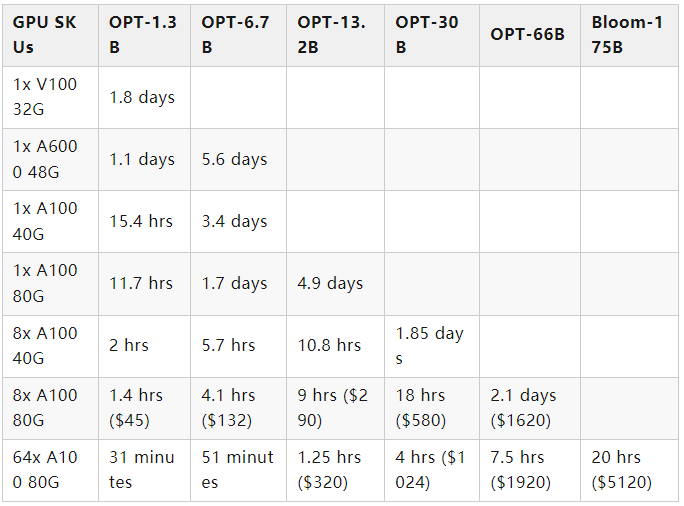
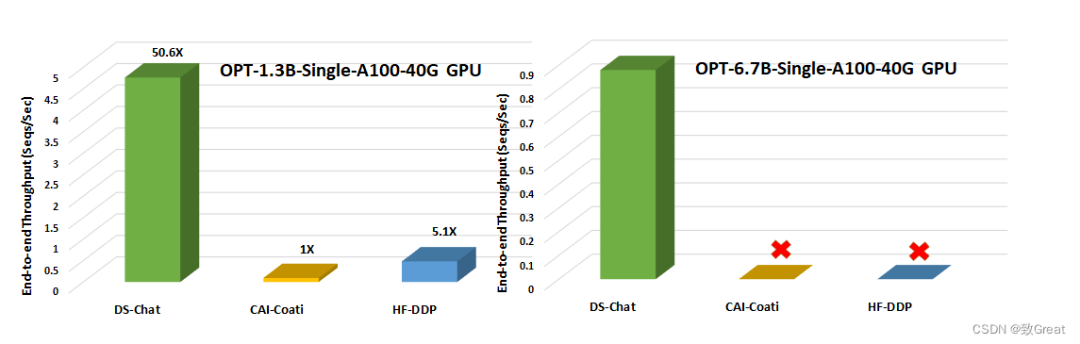
图 2:第 3 步吞吐量与其他两个系统框架(Colossal AI 的 Coati 和 Huggingface-DDP)的比较,用于在单个 NVIDIA A100-40G 商用 GPU 上加速 RLHF 训练。没有图标代表 OOM 场景。
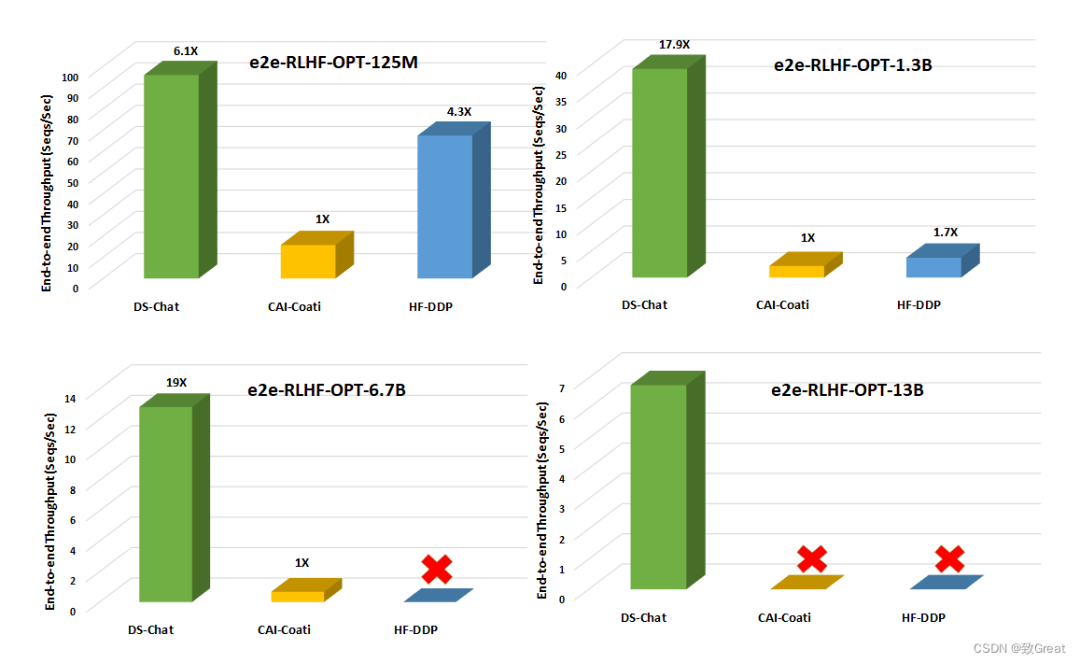
图 3. 在配备 8 个 NVIDIA A100-40G GPU 的单个 DGX 节点上,不同模型大小的训练管道第 3 步(最耗时的部分)的端到端训练吞吐量比较。没有图标代表 OOM 场景。
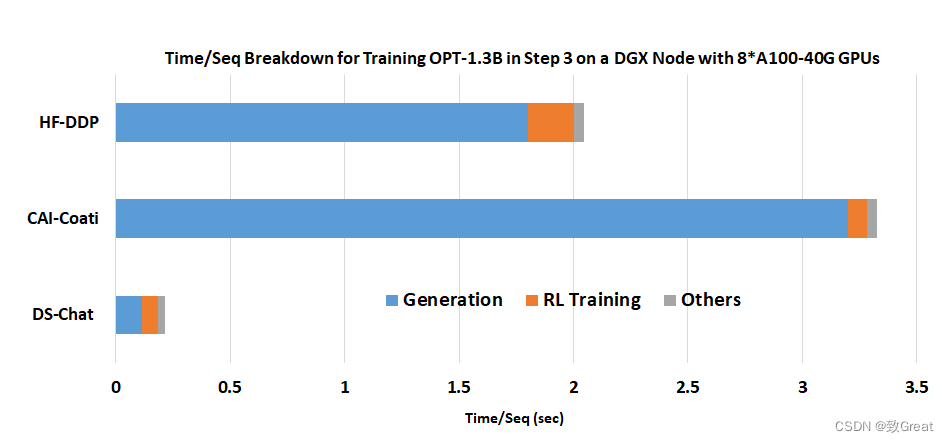
图 4. DeepSpeed Chat 混合引擎的卓越生成阶段加速:在具有 8 个 A100-40G GPU 的单个 DGX 节点上训练 OPT-1.3B 参与者模型 + OPT-350M 奖励模型的时间/序列分解。
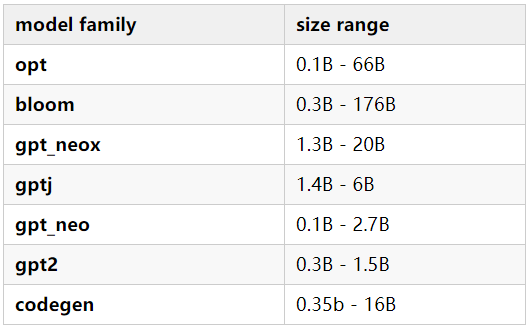
支持的模型
引用
作者:致Great 来源:blog.csdn.net/yanqianglifei/article/details/130141730 版权申明:内容来源网络,仅供学习研究,版权归原创者所有。如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
如果您在领域内有自己的独特见解、落地实践等内容
即刻扫码提交议题

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

