作者 / 来源:中智凯灵 / AiDD

——从北京站议题看企业 Agent 的下一层底座
模型越来越强以后,企业 AI 项目反而暴露出一个更朴素的问题:AI 听懂了自然语言,却不一定听懂企业。
同一个“客户”,在 CRM 里是商机,在财务系统里是合同主体,在客服系统里是工单发起人,在运营看板里又可能是一组分层标签。一个“可交付”,在研发团队眼里是功能完成,在业务团队眼里是流程跑通,在管理层眼里是指标改善。模型可以把这些词解释得很流畅,却未必知道在一家具体企业里,它们分别对应哪些数据、规则、权限、动作和责任边界。
这也是很多企业 Agent 从 Demo 走向生产级时遇到的断点。单次问答可以靠提示词补一补,单个知识库可以靠 RAG查一查,但真正进入业务流程后,问题会变复杂:数据散在不同系统里,Schema 随时变化,不同部门对同一事实有不同口径,历史经验沉在聊天记录和工单里,Agent 想操作下游系统时又缺少清晰的动作边界。
所以,模型越强,企业越需要补一层东西:语义层。
这里说的语义层,不是一套新名词,也不是把知识图谱、本体论、向量数据库或上下文工程简单打包。它更接近企业 AI 的“业务翻译层”:把企业世界里的实体、关系、规则、指标、权限、动作和反馈,转化为 AI 可以理解、系统可以执行、组织可以治理的结构。
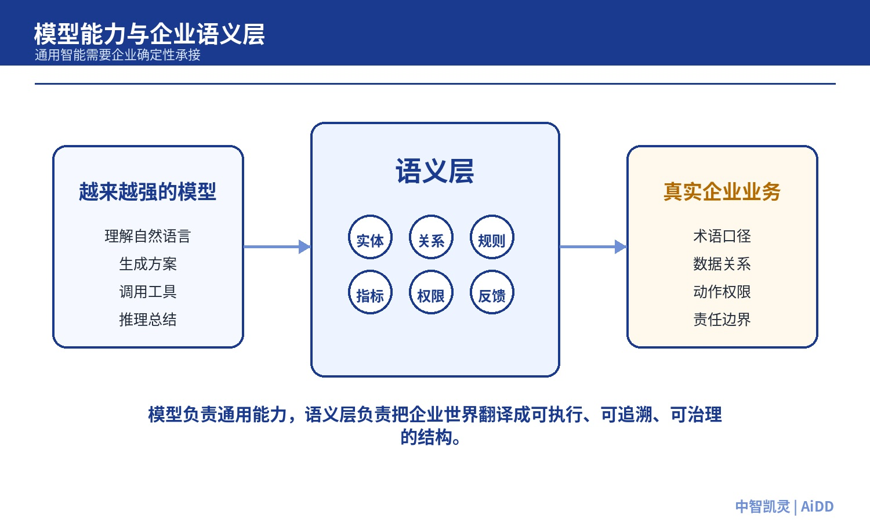
图 1:模型能力越强,企业越需要把业务语义显式化为可执行、可治理的中间层
这正是 2026 年 AiDD 北京站多个论坛共同指向的变化。从《AI 数据工程和知识检索》到《Harness Engineering》,从本体论正本清源到语义孪生、混合搜索、多源实时上下文,核心问题都不再是“模型能不能回答”,而是企业能不能把业务上下文变成可检索、可追溯、可关联、可演进的能力资产。
过去一年,企业做 AI 应用时最常见的起点,是把资料接进知识库,再让模型基于资料回答问题。这个方向当然重要,但它很快会遇到边界。
第一类边界,是词语边界。企业内部有大量只有组织自己才懂的词:业务线简称、客户等级、产品包、项目阶段、故障类型、审批状态、数据指标。模型可以根据通用语料猜意思,却不知道这些词在当前企业里的正式定义、适用范围和例外规则。
第二类边界,是关系边界。一个业务问题往往不在单个文档里,而在多张表、多套系统、多段流程和多类角色之间。只查到一段相似文本,不等于理解了它和其他实体、流程、权限、动作之间的关系。
第三类边界,是执行边界。Agent 不只是回答问题,还会调用工具、生成方案、触发流程、修改系统状态。如果没有语义层告诉它哪些动作可执行、哪些结果要确认、哪些权限不能越过,模型越强,潜在风险也越大。
360人工智能研究院认知引擎算法负责人 刘焕勇在北京站《盲人摸象困境下的“本体论”技术审视及落地观察》中,把这个问题放到了“本体论”重新流行的语境里讨论。他提醒,围绕本体论的说法很多,从 semantic ontology 到知识图谱,再到 Palantir ontology,不同版本的内涵、成本和适用场景并不一样。企业不能把它当成一个即插即用工具,更不能只拿概念包装系统。
这个提醒很重要。语义层不是为了追一个新词,而是为了解决企业 AI 的真实断层:模型有语言能力,但企业没有把自己的业务世界组织成 AI 能稳定使用的结构。
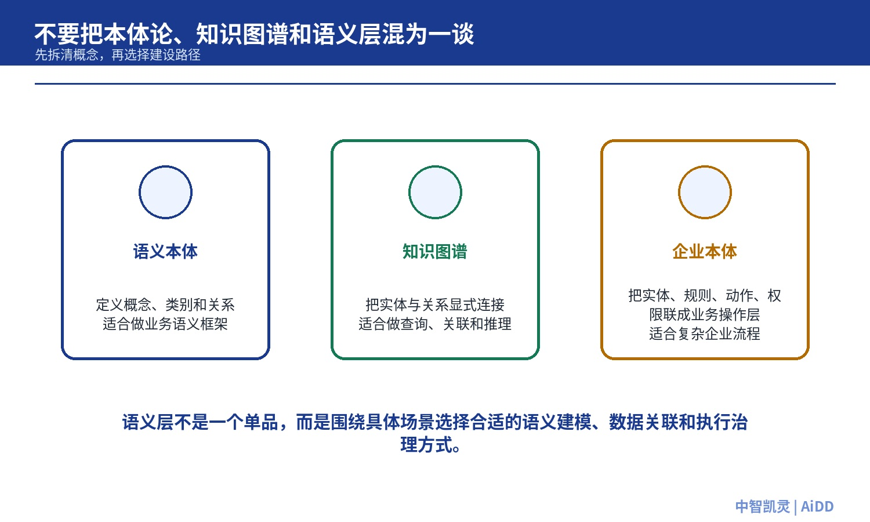
图 2:本体论、知识图谱和企业语义层不是同一个概念,适用边界和建设成本需要被拆开看
换句话说,企业要补语义层,不是因为模型弱,而是因为业务世界太具体。越具体的业务,越依赖本企业的术语、流程、约束和经验。模型可以提供通用能力,但通用能力要进入核心业务,必须经过语义层的翻译、约束和校验。
很多企业第一次搭 RAG 时,会把“语义检索”理解为向量搜索:用户问一句话,系统把问题和文档切片都变成向量,再找最相似的内容。这个方法能解决一部分“关键词不一致”的问题,但生产环境里,仅靠相似度往往不够。
Elastic 中国社区首席布道师 刘晓国在《Elasticsearch向量搜索及 AI Agents 开发》中提到,现代搜索已经不只是简单词汇匹配,也不只是单一路径的向量召回。Elastic 的方向,是把 BM25 关键词搜索、稀疏向量、密集向量、混合搜索、重排序和业务过滤结合起来,让系统既能理解用户意图,也能利用企业已有的查询语法、过滤条件和相关性评分。
这背后其实是语义层的一种现实形态。
用户说“帮我找最近风险较高的客户”,模型可以理解这句话的大意,但企业系统还要继续追问:什么叫“最近”?什么叫“风险较高”?客户范围是哪一类?风险来自逾期、投诉、流失预测,还是合规名单?不同业务线是否有不同阈值?哪些数据源可信?哪些结果必须排除?
如果这些规则只藏在人的经验里,Agent 就只能猜。如果这些规则能进入检索、过滤、重排序和工具调用过程,Agent 才可能把自然语言问题转成更可靠的数据访问和分析路径。
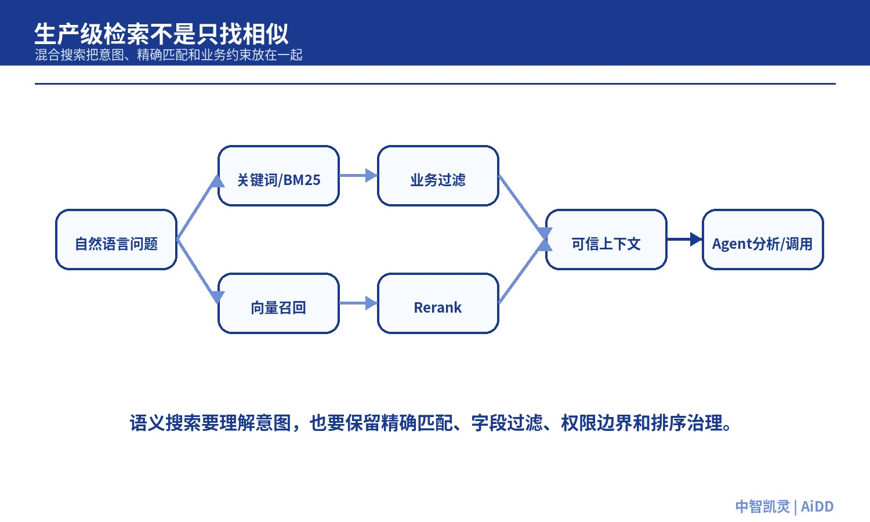
图 3:生产级检索需要把关键词、向量、重排序、业务过滤和权限约束组合起来
所以,企业补语义层,不一定一开始就要建一个宏大的本体系统。更现实的第一步,可能是把关键业务对象、指标口径、字段含义、过滤条件、权限边界和常见查询意图梳理出来,让它们进入搜索与 Agent 工具链。
这也解释了为什么“与数据对话”不能只靠一个聊天框。聊天框只是入口,真正决定回答质量的,是背后有没有稳定的数据目录、语义映射、检索策略、工具定义和结果校验。没有这些,模型生成的答案再自然,也可能只是一次看起来合理的猜测。
企业 Agent 的另一个常见误区,是以为把更多数据接进来,系统就会越来越聪明。
现实往往相反。数据源越多,企业越容易遇到数据分散、Schema多变、上下文腐烂和语义冲突。一个系统里的字段改了,另一个系统还沿用旧口径;一份文档已经过期,却仍被检索命中;两个部门对同一指标有不同解释,模型把它们混在一起;日志、API、数据库和文档都接进来了,但没有统一目录和质量反馈,Agent 反而更难判断什么该信。
阿里云高级技术专家/EventBridge/EventHouse负责人 沈林在《Agent 开发范式演进:简化多源实时上下文构建》中,把这些问题称为Agent 迈向生产级的“深水区”。他的分享提出,企业需要从不断给传统知识库打补丁,转向统一的多源实时上下文构建:一键集成、多源实时感知、统一 Catalog、知识 Wiki、闭环反馈、自我优化,并用可观测、告警和 benchmark 保障上下文变更达到生产级标准。
这说明,上下文工程不是把材料塞进模型窗口,而是把上下文变成可运营对象。
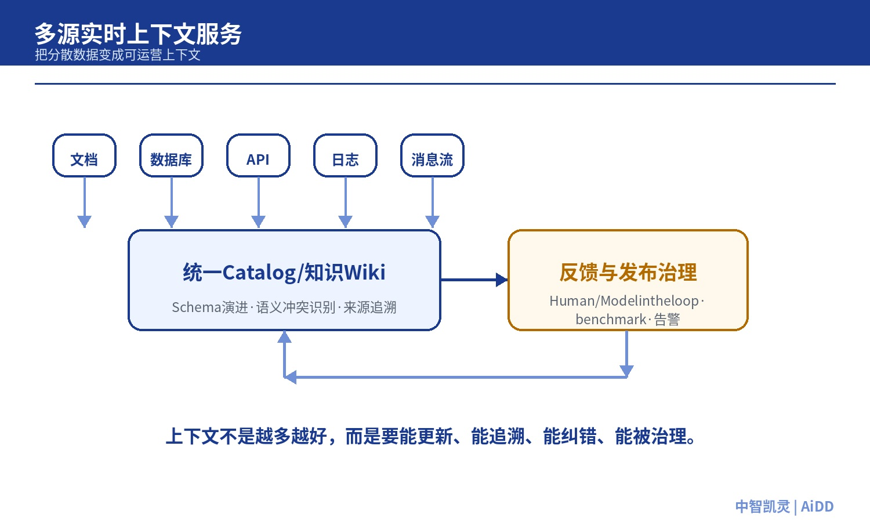
图 4:多源实时上下文服务要处理接入、Catalog、知识 Wiki、反馈纠错和发布治理
在这个视角下,“语义层”承担的不是静态词典角色,而是上下文治理角色。它要知道某个数据从哪里来,什么时候更新,和哪些业务对象相关,是否有冲突口径,哪些反馈说明它需要修正,哪些 Agent 可以使用它,哪些场景必须人工确认。
北京站《Harness Engineering(驾驭工程)》论坛中的 ContextSeek 也指向类似问题。北京奥星贝斯 OceanBase技术专家汤庆的议题提出,通过统一语义层将 memory、trace、knowledge、skill 映射为可检索、可追溯、可关联的上下文对象,并沿 raw、extracted、knowledge、skill 的路径持续进化。它强调的不是“接更多数据”,而是把一次性任务结果转化为长期可复用资产。
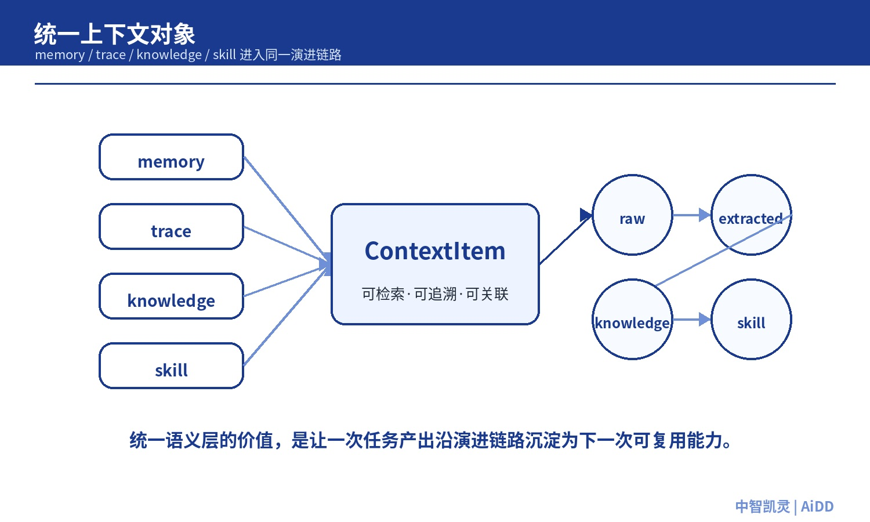
图 5:ContextSeek 代表的方向,是把 memory、trace、knowledge、skill 统一成可演进的上下文对象
这对企业尤其关键。很多 AI 项目不是没有上下文,而是上下文没有生命周期。今天查到的资料,明天可能过期;这次踩过的坑,下次仍然重复;一个 Agent 学到的经验,另一个 Agent 不能继承;一次用户纠错,不能回到知识、规则或 Skill 中。语义层要解决的,正是这些上下文从“信息碎片”到“能力资产”的转换。
当 Agent 开始处理更严肃的企业任务,语义层还会进入更深一层:从知识检索走向业务世界建模。
北京优锘科技解决方案总监 刘钰胜在《基于本体智能的企业级“语义孪生” Agent 实践之路》中提出,大模型在企业级 AI 落地中面临一个根本困境:企业真实业务世界与 AI 认知世界之间存在语义鸿沟。模型听不懂企业术语,跨表查询容易幻觉,想操作下游系统又力不从心。问题根源不在模型能力,而在缺少一套把企业真实业务世界映射到 AI 认知空间的“语义孪生”体系。
“语义孪生”这个说法,比普通知识库更进一步。它不是复制物理世界的几何状态,而是对企业业务世界里的概念、关系和规则做高保真语义映射,让 Agent 能理解、能推理、能操作。
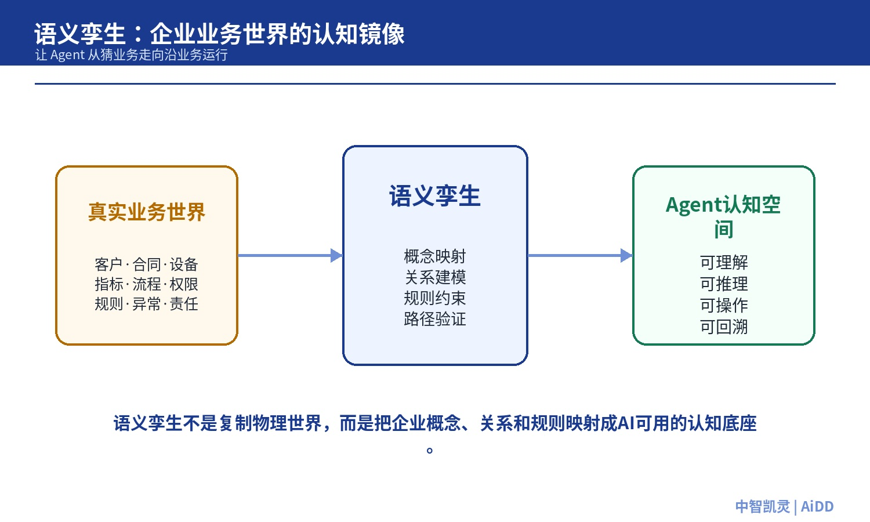
图 6:语义孪生把企业业务世界映射为 Agent 可理解、可推理、可操作的认知底座
以智能问数为例,传统 Text-to-SQL 很容易在严肃生产环境里遇到准确率天花板。原因不是模型不会写 SQL,而是它不知道企业指标的真实口径、表之间的业务关系、字段背后的含义、用户问题的隐含约束,以及哪些答案需要经过权限和风险校验。语义孪生要做的,就是让 Agent 不再凭概率猜表、猜字段、猜关系,而是沿着业务本体、语义图谱和规则约束生成更确定的路径。
这也是企业 AI 从“能用”到“敢用”的分水岭。
“能用”阶段,企业关注模型能不能回答、能不能生成、能不能调用工具。“敢用”阶段,企业会追问另一组问题:它为什么这么回答?它用了哪些数据?它是否理解了业务口径?它有没有越过权限?它调用这个动作是否符合流程?结果错了以后能不能回溯和纠正?
这些问题都不是单靠更大的模型窗口就能解决的。它们需要业务建模、数据语义融合、场景推演、调用路径验证和上线后的持续运营。语义层不是替代模型,而是给模型一个能进入企业核心业务的认知底座和操作边界。
讲到这里,很容易把语义层想得过重,好像企业必须先做完一套庞大的本体工程,才能开始做 Agent。这个理解也有风险。
刘焕勇对本体论热潮的提醒就在这里:本体论有强运营、强人工和高构建成本,不能被包装成即插即用的工具。企业真正需要的,不是概念上“有本体”,而是能够围绕关键场景持续建设、验证和迭代语义资产。
更务实的路径,应该是从一个高价值场景开始,而不是从全企业抽象模型开始。
比如,先选一条真实业务流程:客户风险识别、智能问数、研发需求澄清、运维故障诊断、运营活动复盘。围绕这条流程,梳理核心实体、关键关系、指标口径、动作权限、异常样本和人工接管点。再把这些结构接入检索、工具、评估和反馈系统。用少量真实任务验证它是否让 Agent 更准确、更可控、更可复用。
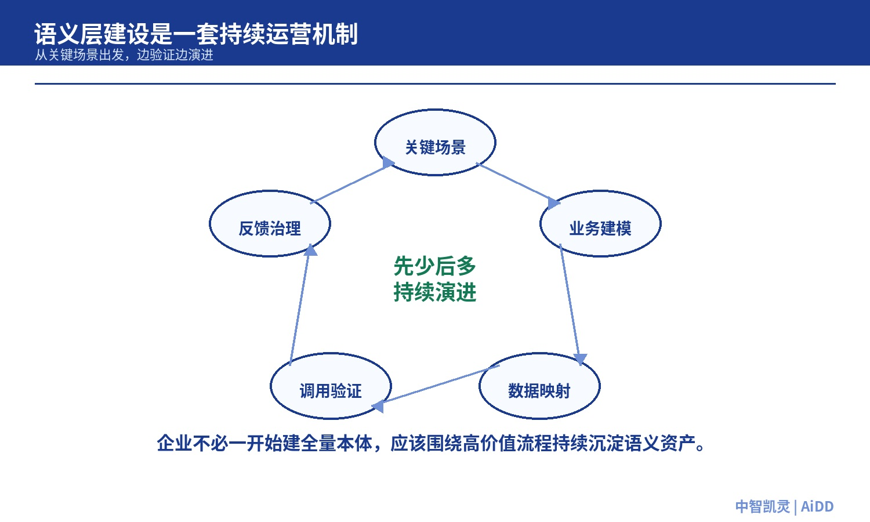
图 7:语义层建设应从关键场景出发,通过建模、映射、调用、反馈和治理持续演进
这个过程和传统数据治理有相似之处,但目标不同。传统数据治理更多面向报表、分析和合规;AI 时代的语义层还要面向 Agent 执行。它不仅要回答“这个字段是什么意思”,还要回答“这个 Agent 在什么条件下可以使用它”“这个动作能不能自动执行”“这个结果需要谁确认”“这次反馈应该回写到哪里”。
因此,语义层最后会落到组织机制上。它需要业务专家定义概念和规则,需要数据团队处理来源和质量,需要工程团队把语义映射进检索、工具和系统接口,需要安全与管理团队设置权限、审计和接管机制,也需要一套持续运营流程,让新的业务变化、用户反馈和 Bad Case 能不断回到语义资产里。
Inspire AI产品总监 钟健鑫在《Agentic 组织演进:从“人驱动”到“任务驱动”的新范式》中提到,企业级动态本体和共享语义知识体系,是让 Agent 理解业务上下文、跨部门协同、持续更新的重要基础设施。这个判断把语义层从技术问题推回了组织问题:如果企业仍然按部门墙管理知识和流程,Agent 也很难跨部门稳定协作。
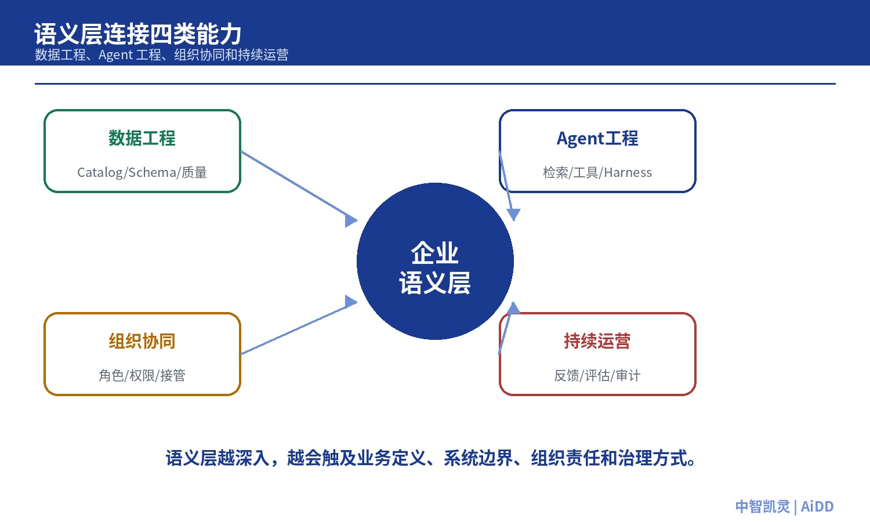
图 8:语义层最终连接数据工程、Agent 工程、组织协同和持续运营
所以,语义层不是一项后台工程,而是一套企业 AI 的运营机制。它越往深处走,越会触及业务定义、系统边界、组织责任和治理方式。
企业补语义层,并不是对大模型能力不信任。恰恰相反,正因为模型越来越强,企业才更需要把自己的业务世界整理成模型可以稳定使用的结构。
通用模型解决的是语言理解、生成推理和工具调用的通用能力;语义层解决的是企业内部的确定性:术语怎么定义,数据怎么对齐,关系怎么表达,动作怎么约束,反馈怎么回写,经验怎么复用,责任怎么追溯。
没有语义层,企业 AI 很容易停在“强模型 + 散上下文”的状态:一次演示很顺,一到真实业务就开始猜字段、猜口径、猜权限、猜流程。有了语义层,Agent 才可能从聊天入口走向业务接口,从单次问答走向持续运行,从个人效率工具走向组织能力资产。
这也是《知识库、Skills 与组织资产》之后,企业 AI 落地自然会追问的下一层问题:知识如何被组织起来?上下文如何持续更新?本体如何避免空转?搜索如何兼顾语义和精确?Agent 如何沿着企业真实业务世界运行?
语义层的故事,北京站会继续展开。
相关议题
下一站
当企业从“把资料喂给模型”进入“让 Agent 进入真实流程”,更需要讨论的就不只是知识库,而是本体、混合检索、上下文工程、语义孪生和动态业务语义如何共同构成生产级 Agent 的底座。
2026 年 AiDD 北京站,将在上海站的基础上继续深挖:AI 数据工程和知识检索、Harness Engineering、Agentic 组织架构演进,以及企业智能体从 Demo 走向生产级所需要的上下文、语义和治理能力。
模型会继续变强,但企业真正要补的,是让模型进入业务世界的那一层确定性。
北京,我们继续聊。

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

