以下文章来源于丁辉的软件架构说 ,作者丁辉 架构师

随着人工智能技术的飞速发展,大模型在代码生成领域的应用日益广泛。目前,业界主流的代码生成方式主要基于大模型编码,其中又以问答式和Copilot方式为主。然而,这些方式在实际应用过程中都面临着一系列挑战,尤其是在处理长提示词时遇到的问题尤为突出。
在问答式编码中,无论是zero-shot、few-shot还是动态prompt,都依赖于精心设计的提示词来引导大模型生成代码。然而,过长的提示词不仅增加了prompt模板的维护成本,也对模型的兼容性和推理速度带来了负面影响。更为严重的是,长提示词往往导致模型推理过程中丧失焦点,局部细节精准度下降,从而影响了代码生成的效果。
下面就带大家仔细分析下编码业界主流有两种方式(github workspace智能体方式目前仅限于特定场景):
1、zero-shot
简单的通过自然语言直接与大模型进行问答,一问一答,大多数根据上下文进行多轮对话生成代码。
2、few-shot
通过完整提示词(一般为ICIO方式,包含指令+上下文+单案例或多案例(多few)+输出指示)的方式进行代码生成。
3、动态prompt
类似第二步few-shot,在prompt模板中预留变量占位符,通过各种工具链中的RAG查询向量库、数据库、知识图谱库等外部知识源,获取内容格式化后替换到prompt模板变量中,形成场景化的prompt,然后跟大模型交互生成代码。
以上几种方式目前虽然被主流使用,但都会产生提示词过多、提示词(zero-shot会造成多轮对话上下文进入提示词过长的问题)过长的现象,而过长提示词又会带来一系列问题:
a、prompt模板维护成本高
业务功能中不同的场景需要不同的prompt模板,很多大型系统业务场景不胜枚举,如果没有很好的管理,对应的prompt模板的数量也会急剧增多。
加上提示词模板快速演进,需要同步和调测prompt模板的工作量也会相应增加,维护成本较大。
b、prompt模板对模型兼容性不足
目前大模型演进和更新日新月异,不同的大模型对相同的提示词模板都或多或少存在很多问题,甚至相同大模型不同的版本间也存在着不小的差异,这就造成了模型替换或升级时,提示词模板兼容测试、调整的巨大工作量。
c、prompt token数过大
尽管现在很多模型输入+输出token数都达到了8k,但是对于使用few-shot的场景,特别是few3和few4或者上下文代码大量加入的,输入+输出token数很多都会超过4k+4k或6k+2k,造成大模型输出的token超限被截断。
d、推理速度过慢
超大的输入token会造成推理集群的巨大负担,导致整个推理资源被并发挤占,整个集群的反馈速度都会被拖累下来,严重影响用户体验。
e、局部细节精准度下降
提示词过长会造成模型推理过程中丧失焦点,很容易造成模型跟随能力下降,局部问答效果准确性严重下降,幻觉问题大幅抬升。
f、调试成本高
长提示词生成代码中,如果局部准确度有问题,需要反复调整提示词,让大模型不停重新输出。
但由于长提示词带来的焦点丢失问题,让代码生成的效果很难确定性调整到位,整改过程很多时候让人觉得用提示词编程就想隔靴搔痒、抓耳挠腮,实在不行还是手工修改代码,这又会造成提示词和代码不一致,提示词模板慢慢变得没有意义。大家又会吐槽大模型能力不行,就更不愿意使用长提示词了。
为啥会出现这种情况呢?
我们从大模型的边界说起,大模型本质是个语言模型,准确的说是语言统计模型,即在一定上下文下,根据训练语料中下一个词、句、段落出现的统计学概率来决定生成内容。
对于编码来说,通用知识对应的代码在语料中比较充分、且训练和精调也比较充分,导致它们在推理过程中出现的统计学概率高;
而私域知识本身对于大模型整个语料中占比相对较低,自然在推理过程中统计学概率不高,造成生成效果不足。
所以长提示词好用的前提是取决于大模型私域能力注入的程度如何,显然很多大模型都没有进行私域知识的充分注入,甚至很多自研大模型由私域代码的增量预训练,但私域代码训练语料相对于通用知识语料的占比太小,同时增量云训练和精调的程度有多多少少跟原模型不正交,造成效果会有相应的折扣。
综上,针对这种情况我们还是给出旗帜鲜明的观点:
当前阶段主流大模型的能力还只能实现基础编程能力的知识平权,即使对于私域领域大模型,私域语料的占比也较低或者训练不充分,对于强私域场景,很难实现活动级的端到端全自动软件开发。
建议对于编码高频场景,还是要把私域知识剥离,即把业务流程和业务逻辑拆解开,以短提示词(输入token 2k以内)+通用知识的方式跟大模型交互,获得确定性效果,原理见下图,也可以参见我的公众号文章《如何使用大模型高效代码生成,请用确定性prompt》:
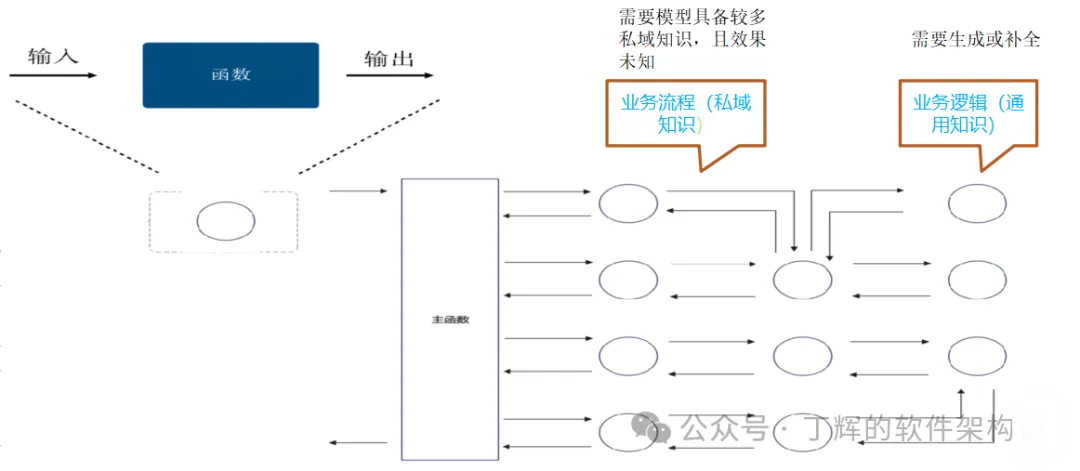
长提示词仅适合生成生成代码框架的低频场景。
二、copilot方式
copilot方式可以更精准组织短提示词,来进行代码补全,同时不需要开发人员个体维护提示词模板。
代码补全的本质是通过编程IDE来抽取工作空间中上下文并合理组织成精细化短提示词,获得更加明确的效果。
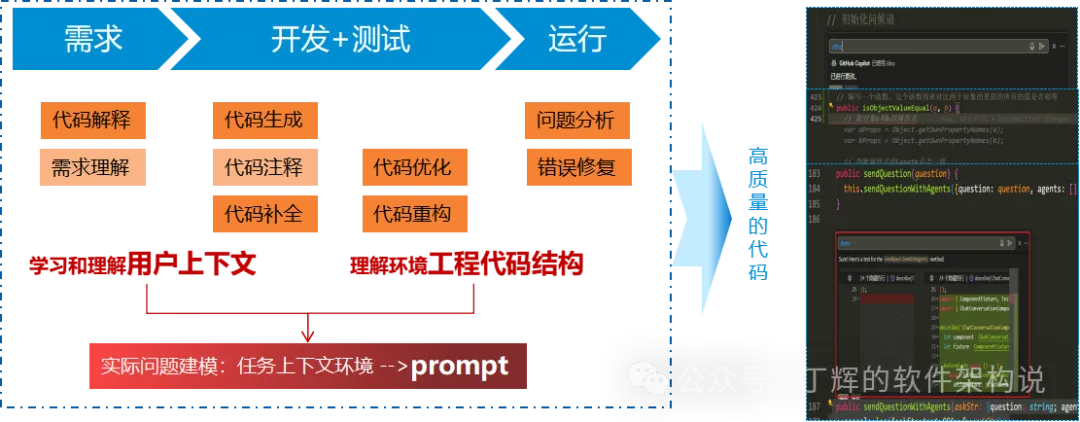
见上图,代码补全可以实现代码解释、需求理解、代码生成、代码注释、代码补全、代码优化、代码重构、bugfix等编码阶段的主要场景。
其中代码补全又是高频核心场景。
从补全细分场景看:
1、行内随手补
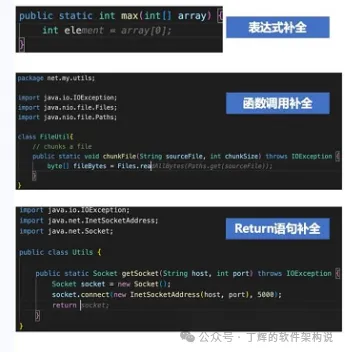
2、单行补
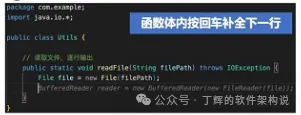
3、块补
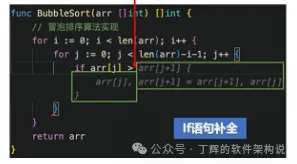
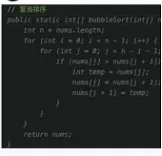
控制流程补
注释补
函数补
以上代码补全的场景要点都是尽可能从当前打开代码中获取任务上下文推测用户意图,生成精细化的prompt,降低提示词长度。
如何获取尽量精准的上下文信息呢?
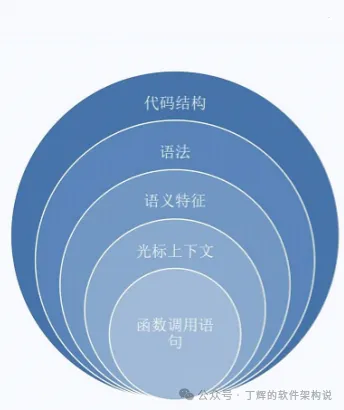
首先拆解打开的当前文件的代码结构,分成全局变量/全局函数、类成员变量/成员方法等;
然后对光标所处结构进行语法分析,形成AST;
然后在AST中搜索相对完整的语义特征(光标前后都需要);
接着增加被调用函数的原型(从其他打开的问题、工程、或知识库中获取);
再然后还可以把工作区和选定知识库的代码进行RAG,把近似参考代码也取出来;
最后把上述部分作为精准提示词送给大模型进行代码补全,当然模型必须经FIM的精调,否则会造成过度输出。
综上,目前大模型的能力还是处在大模型辅助人的阶段,目前大模型生成代码建议采用问答和copilot结合的方式进行。
首先采用问答式长提示词方式生成代码框架,这种属于低频场景;然后采用以下方式应对高频:
1、使用经过私域知识剥离(分离业务流程和业务逻辑)的短提示词,生成具备通用知识的代码来承载业务逻辑,业务流程通过人工进行串接。
2、使用copilot,精准识别用户意图以获取光标上下文的语义特征,同时满足最小提示词的要求,通过小模型生成高准确率代码。
既有阳春白雪又要下里巴人,既要高瞻远瞩,又要立足当下。
雄关慢道真如铁,而今迈步从头越。
作为“K+全球软件研发行业创新峰会”的往届演讲嘉宾,丁辉诚邀您共赴K+峰会上海站。本届峰会将于6月21-22日上海举办,峰会邀请了来自(谷歌、微软、Intel、阿里)等一线互联网大厂嘉宾,分享AI从研发全栈的应用到商业价值落地的创新实践案例。

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

