本文整理自“软件工程3.0”定义者/CCF杰出会员、质量工程SIG主席朱少民老师在AiDD峰会2024深圳站上做了主旨演讲,讨论的主题是“大模型时代软件研发正确打开方式”,深入探讨了大模型对软件研发的影响,以及如何在软件研发中正确地落地实施LLM,演讲大纲:
国内LLM落地软件研发的现状
LLM更适合编程工作吗?
代码生成的正确打开方式
软件研发终极打开方式
未来展望
一、国内LLM在软件研发中的现状
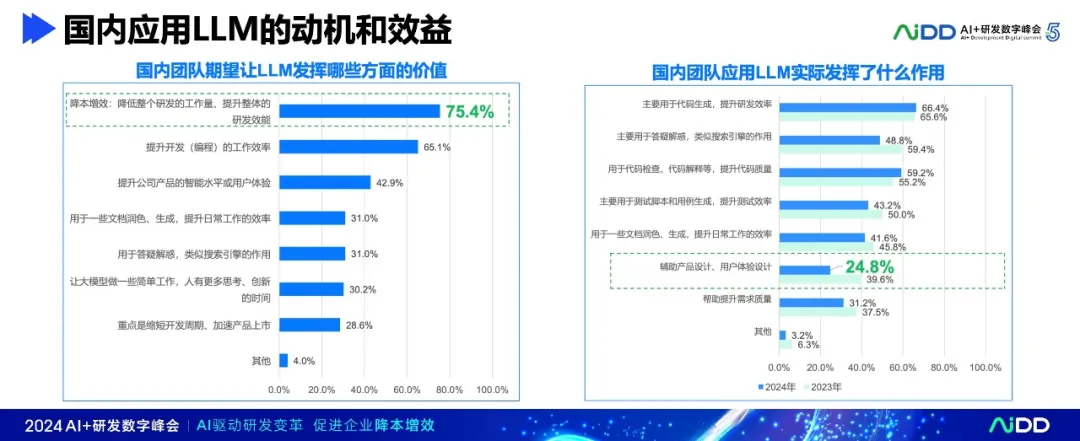
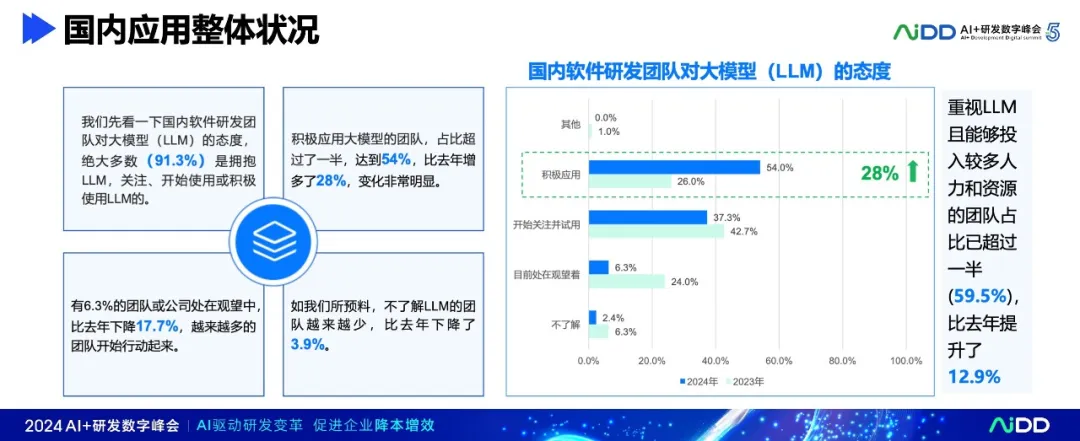
根据《2024软件研发应用大模型国内现状调研报告》显示,国内的软件研发团队对LLM的重视程度显著提升,绝大多数的团队(91.3%)拥抱大模型。积极应用大模型的团队,占比超过了一半,达到54%,比去年增加了28%,进步非常明显;超过59.5%的团队表示能够投入较多的人力和资源,比去年提高了12.9%。这表明越来越多的团队开始认识到LLM在软件研发中的潜力。
在软件研发整个生命周期(从需求、设计到编程、测试等),国内团队都有很好的应用,有近35%-50%的团队都取得比较显著的效率提升(效率提升20+%),目前在编程环节LLM应用效果最好。
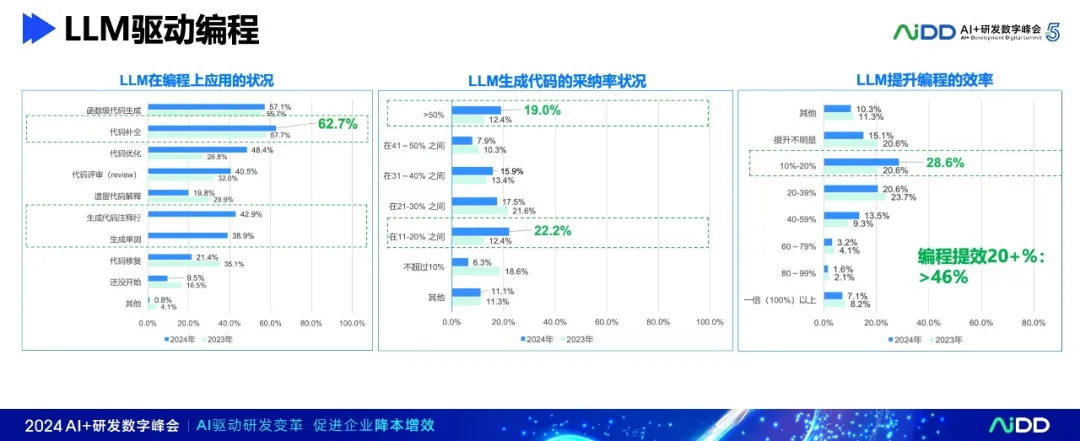
然而,尽管有积极的态度,团队在应用LLM时仍面临诸多挑战。例如,生成代码的采纳率依旧很低,主要集中在11-40%之间;在需求、设计、测试等环节的应用还不够好,而且多数LLM应用还是局限在单个点(环节)、局部应用,而不是从需求开始形成完整的链条,这样也导致效率提升不明显。正如,许多人常常说,开发人员不只是写代码,写代码的时间只占工作时间的20%左右,仅仅用于代码生成,而且代码采纳率这么低,自然提效不明显。其实,我们可以问两个问题:
- 那80%的时间在干什么?是不是有很大的优化空间?(这不属于AI的问题,但值得开发人员反思,在需求建模、设计上的投入如何?是不是浪费了太多时间在沟通、开会上?)
此外,团队在技术应用过程中也面临着一些常见的问题,涉及大模型应用的一些关键要素,如:
由AiDD组委会联合多个社区发起的「2024软件研发应用大模型」调查结束了,报告已在11月8日AiDD峰会深圳站主会场Keynote重磅发布。扫描下方二维码即可免费下载调研报告!
二、LLM更适合编程工作吗?
在LLM实际应用过程中,“主要用于代码生成,提升研发效率”、“用于代码检查、代码解释等,提升代码质量”排在企业(团队)应用的第一、二位,而且各个大厂也都开发了基于LLM的编程助手,如腾讯云AI代码助手、盘古编程助手、文心快码、通义灵码等,这说明,在LLM应用上,企业首先、重点投入在编程(开发)环节。
你可能会问,为何我们会重点投入在“LLM+编程”上呢?
1. LLM适合编程的三大理由
1)高成本的开发人员:软件公司的主要成本是人力成本,而人力成本中开发人员的成本是大头,例如开发人员和测试人员之比常常是3:1、4:1,更高的是5:1到10:1,所以企业首先想利用LLM来降低开发人员的成本或提高开发人员的工作效率。
2)高质量的代码数据:编程领域拥有大量高质量的公开代码库,企业内部代码的质量也是有保证的,毕竟这些代码已通过测试、得到实际运行的验证,为LLM的训练提供了丰富的、高质量的语料,从而能训练出高质量的代码大模型。
3)编程语言也是一种语言:从语言模型的角度看,编程语言的语法和结构可以被视为自然语言的特殊形式,具有规则性和一致性,和大语言模型(LLM)一脉相承。

2. LLM的局限性——幻觉问题
然而,LLM作为一种概率模型,在生成代码时可能出现幻觉问题:
- 数据产生的幻觉:由于错误的数据源、知识边界的限制或数据利用不当,模型可能生成不正确的代码。
- 训练相关的幻觉:预训练过程中的缺陷、对齐问题和能力不匹配可能导致模型生成的代码不符合预期。
- 推理相关的幻觉:解码策略的缺陷和上下文注意力不足可能导致模型生成错误的或不完整的代码。
代码要求高度的准确性,哪怕是一个符号的错误都可能导致程序无法运行。因此,我们需要采取措施缓解幻觉问题:
- 数据层面:增强数据质量,明确知识边界,确保模型使用正确的数据源。
- 训练层面:改进预训练过程,优化对齐目标,提升模型对编程任务的适应性。
- 推理层面:增强解码策略,加强上下文信息的利用,提高模型生成代码的准确性。
上述措施可以缓解幻觉问题,但不能根本解决问题。那么如何生成稳定的、高质量代码呢?
三、代码生成的正确打开方式
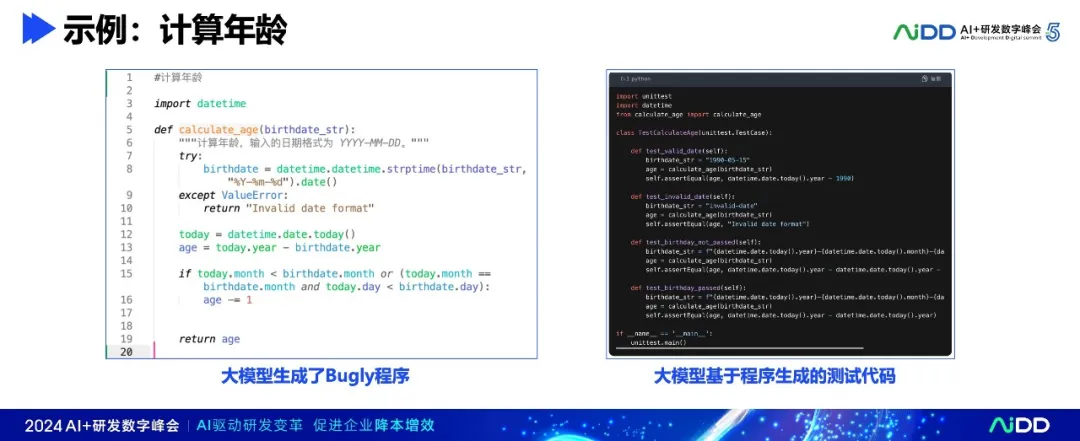
目前国内流行的AI编程助手,都是先生成代码,再基于代码生成单元测试。然而,这种方式往往存在很大的风险:如果代码本身存在错误(特别是那些缺失某些约束条件的代码),那么基于这样错误代码生成的测试不会对所缺失的条件进行验证,从而无法发现这类问题。演讲中,所举的“计算年龄”例子,生成的代码有两个条件(参数是否异常、今年的生日是否过了)判断,生成的测试代码就只验证这两个条件,所以只生成了4个用例的测试代码。而实际情况复杂,不只是这两个条件,见下面内容。
为了克服上述问题,我们可以让大模型想一想如何验证要实现的功能,然后生成测试代码,我们可以检测生成的测试代码,再基于正确的测试代码生成产品代码。具体步骤如下:
- 第一步:让大模型思考如何验证要实现的功能,先想清楚:如何全面验证所实现的功能。即利用LLM生成验证点,再基于验证点生成测试代码。
- 第二步:生成代码。基于测试代码,让LLM生成能够通过测试的产品代码,确保函数能够正确处理各种约束条件和边界情况。
- 第三步:验证代码。运行测试,确保代码通过所有的测试用例。
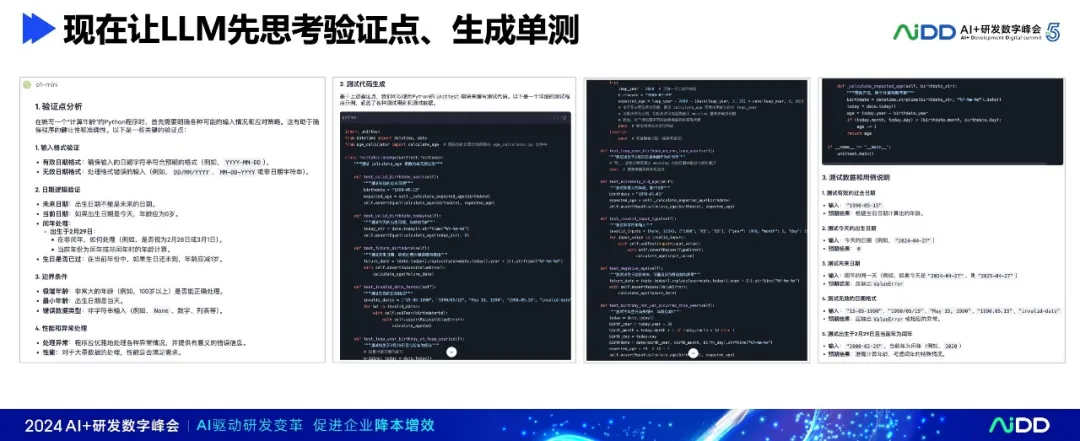
(不是4个测试用例,而是12个测试用例。这也说明,之前基于代码生成单测的质量明显不足。)

(基于上述测试代码生成的产品代码考虑了各种情况,具有很好的容错性、可靠性,才是高质量的)
所以说,在大模型时代,UTDD(Unit Test Driven Development)凤凰涅磐、重焕生机,即在大模型时代,代码生成的正确打开方式是UTDD:先生成单元测试代码,给代码生成足够的上下文和约束条件,再根据测试代码生成产品代码,可以最大程度缓解LLM的幻觉,更好地保证生成代码的质量。过去,我们为何没有这么做?TDD为何死了?因为过去靠我们写测试代码、产品代码,开发往往需要两倍的时间,我们的计划往往不可能给这么多时间;而且许多开发人员缺乏测试能力,不知道如何做测试。今天LLM可以指导开发人员做测试,可以基于测试方法生成测试代码。基于LLM生成测试代码,开发人员快速检查和完善测试代码的时间很少,然后再基于测试代码生成程序,也很快。今天实施TDD,比过去只写产品代码(不做单测)的时间还少。初步估计是:效率可提升150%:
- 过去手工做TDD或完成“代码编写+充分的单测”:两周
- 今天LLM生成单测(+人工检查)+再基于测试代码生成产品代码(+人工检查/调试):2天
四、大模型时代软件研发的落地方式
LLM是大语言模型,特别适合文字处理的工作,今天LLM翻译已能达到一次性可用的地步,天下无敌。LLM在自然语言处理方面的优势,在借助智能体(AI agent)和RAG技术,使其非常适合用于需求的采集、分析和定义。通过与用户的交互,LLM可以将模糊的需求转化为明确的用户故事(User Story)和验收标准。

ATDD(Acceptance Test Driven Development)即验收测试驱动开发,是一种以用户需求为核心的开发方式。在大模型时代,ATDD的过程可以利用LLM进一步优化:
- 定义用户故事及验收标准:与用户或需求方协作,利用LLM将需求转化为清晰的用户故事和验收标准,例如采用Given-When-Then(GWT)格式。

- 生成测试代码:基于验收标准,利用LLM自动生成验收测试代码(通常是集成测试或端到端测试)。
- 生成应用代码:在测试代码的指导和约束下,利用LLM生成能够通过所有验收测试的应用代码,包括前端和后端的代码。
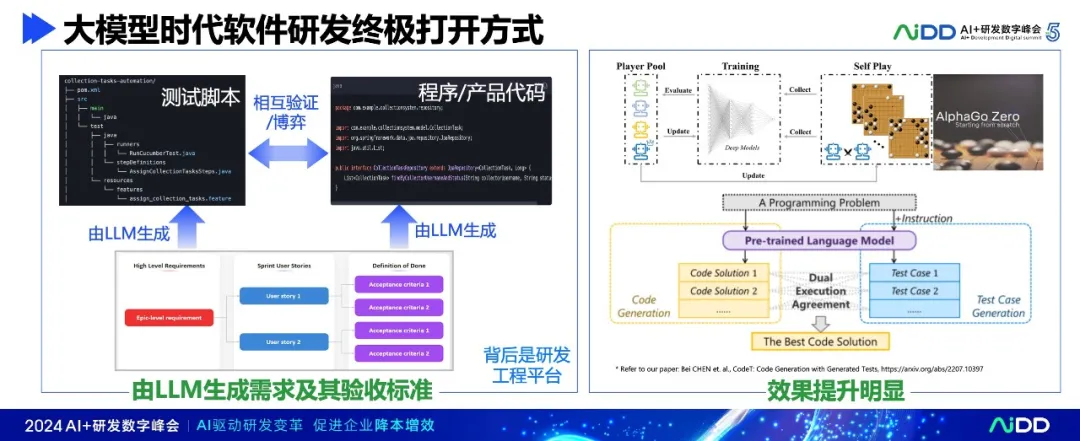
在大模型的支持下,软件研发可以实现从需求到测试、再到代码的全流程自动化:
- 由LLM生成需求及其验收标准:明确用户需求,生成清晰的验收标准,相当于进一步澄清需求,而且可以做得又快又好。
- 由测试大模型或盘古研发大模型生成测试脚本:根据验收标准,自动生成测试用例和脚本,确保功能满足需求。
- 由代码大模型或通义大模型(不同于测试生成的大模型)生成程序/产品代码:在测试的指导下,生成高质量的代码。
- 然后让生成的测试和生成的代码相互验证、相互博弈,输出更高质量的测试代码和产品代码。例如,测试运行之后,可以发现代码的问题,将错误信息反馈给代码大模型,让它重新生成产品代码。代码LLM也能发现测试的不足,例如某些代码未被覆盖,把未覆盖的信息反馈给测试大模型,让测试大模型补充测试用例、提升测试覆盖率。
这样的思想,在AlphaGo/AlphaZero、微软论文、OpenAI O1 IoI模型中得到验证。
要实现上述流程,需要一个强大的研发工程平台作为支撑,整合LLM、自动化测试和持续集成等工具,提供一体化的开发环境。通过这种方式,开发效率和质量都将得到显著提升:
开发和测试有了同源:高质量的需求,但又相互独立工作,且以测试(质量)为前提进行,代码一次性生成的成功率很高,代码采纳率得到大幅度提升。
验证点、断言的生成有了明确的、正确的需求支撑,容易生成。现有的机器学习方法能够提升断言的成功率,但极其有限。
开发效率提高:从需求到测试、再到开发,上下文自然生成,形成流水线操作,自动化程度更高,人工操作工作量显著降低。
代码质量提升:严格的测试驱动确保了代码的可靠性和稳定性。
所以说ATDD是大模型时代软件研发的终极打开方式。
五、未来展望
随着AI技术的不断发展,计算机将更深入地理解现实世界,推动软件研发进入智能化时代。从LLM在编程中的应用,到UTDD和ATDD开发模式的引入,再到未来多智能体的协同开发,AI正在重塑软件开发的每一个环节。
1. 多智能体协同开发软件
未来的软件开发将不再只是人类开发者的专属领域。多智能体系统(Multi-Agent Systems)将在开发过程中扮演重要角色。智能体/数字人和开发人员共同协作,实现更高效、更智能的软件开发。
2. 自主智能的软件研发平台
未来的软件研发平台将具备一定的自主能力,实现智能化的决策和开发,将具有实时自动化决策(Real-time Automated Decision-making)、自主AI代理(Autonomous AI Agents)等能力,
作为软件行业从业人员,我们需要不断学习,拥抱新技术,与AI协同工作,积极探索和实践,找到大模型时代软件研发的正确打开方式,以应对挑战,抓住机遇,实现更高效、更智能的软件开发。
想要朱少民老师ppt分享详细内容的请点击阅读原文进入AiDD峰会官网下载。